AI봇의 습격과 의적 홍딥식이라는애플코딩님의 이야기를 듣고 찾아봤다
몇년뒤에는 정말 현실화 될것같다
4:45부터
↓https://www.youtube.com/watch?v=mni4_Ktwvhw

공식 홈페이지에서 DeepSeek 모델을 사용하면 각종 주제에 대한 검열이 있을 수 있다.
하지만 R1을 비롯한 DeepSeek의 LLM 모델들은 전부 오픈 소스로 자유롭게 개방되어 있으므로 누구나 직접 LLM 모델을 자신의 기기에 내려받아서 구동시킬 수 있다. 이 경우 인터넷 연결 없이도 LLM 모델을 사용할 수 있으므로 앞서 언급한 다양한 문제를 상당 부분 해결할 수 있으나, 동시에 검색 기능을 지원하지 않아 직접 구현해야 한다는 단점도 존재한다.
많은 화제를 끈 R1 원본 모델의 경우 약 500GB 수준에 이르는 메모리 용량을 요구하지만 추론 패턴 전이 및 양자화(비트넷)를 비롯한 다양한 경량화 기법들이 적용된 가벼운 모델들도 폭넓게 제공되고 있다.
직접 로컬 환경에서 DeepSeek 모델을 사용해보고 싶다면, GGUF 형태로 변환된 모델을 내려받아 이를 구동할 수 있는 프로그램이나 애플리케이션을 통해 사용하면 된다.
현재 Windows, MacOS, Linux 환경에서는 Ollama가, 그리고 iOS 환경에서는 PocketPal, Private LLM 등의 애플리케이션이 R1 기반 모델을 지원하고 있으며, 8GB 수준의 메모리 용량을 갖춘 기기라면 Llama-8B 내지는 Qwen-7B에 기반한 모델이 권장된다.
한편, R1의 원본 수준 모델(671B)을 로컬 환경에서 구동하고 싶다면 Apple Silicon이 탑재된 Mac을 클러스터링하는 방법이 있다. Apple Silicon의 통합 메모리 용량은 옵션에 따라 정해져 있으며 사용자가 직접 용량 업그레이드를 할 수 없다는 점에서 고객들로부터 원성을 사기도 했지만, 메모리 대역폭이 엄청나게 늘어나면서 LLM을 빠르게 구동시킬 수 있다.
예시로 NVIDIA H200 SXM 141GB[11]의 경우 1개당 약 4900만원에 이르는 반면, 2023년형 Mac Studio 192GB[12]는 1대에 839만원에 불과하니 가성비(!)가 엄청난 것이다. # 예를 들어 3비트 양자화된 모델을 구동하려면 H200 구성으로는 단순계산만으로 3대(1억 4700만원 상당)가 필요하지만, Mac Studio를 쓴다면 2대(1680만 원 상당)만으로 해결할 수 있다.
실제 구동 동영상은 아래 엑스에서 볼수 있다.
DeepSeek R1 671B running on 2 M2 Ultras faster than reading speed. Getting close to open-source O1, at home, on consumer hardware. With mlx.distributed and mlx-lm, 3-bit quantization (~4 bpw)
↓https://x.com/awnihannun/status/1881412271236346233
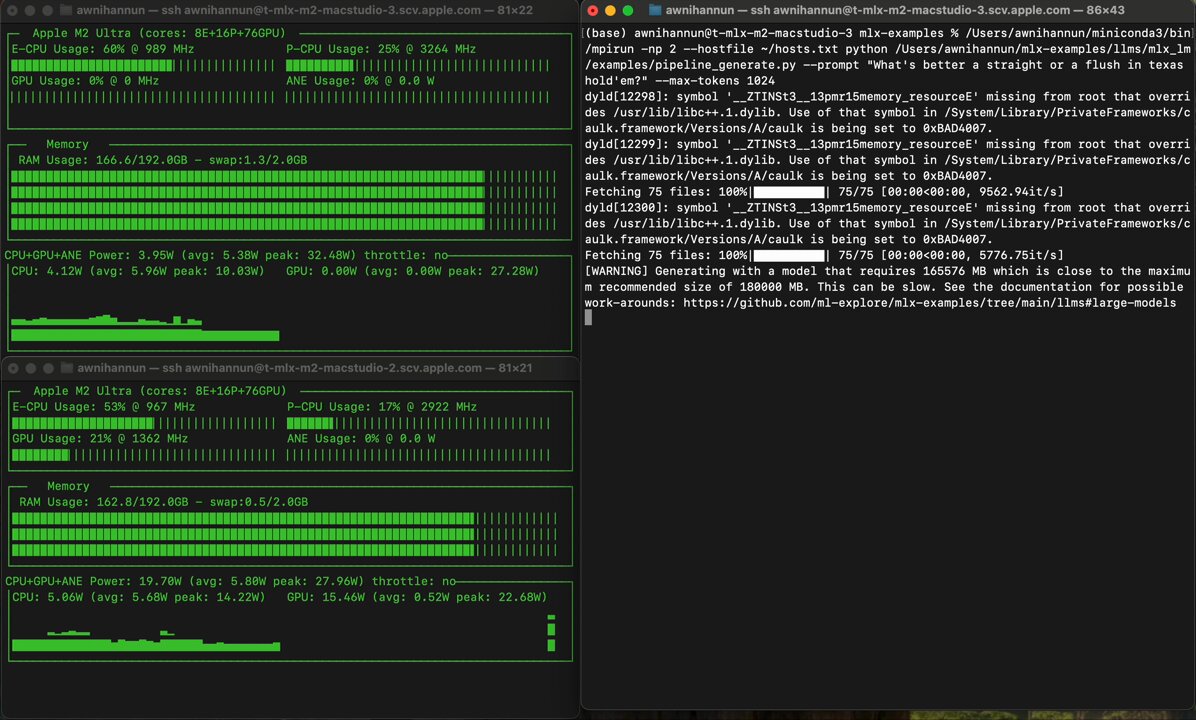
↓X에서 Awni Hannun 님 DeepSeek R1 671B running on 2 M2 Ultras fa.mp4