Hot Chips 2021 컨퍼런스에서 인텔은 M1을 벤치마킹하고 크고 작은 코어 BigLittle 아키텍처를 사용하는 12세대 아키텍처 alderlake를 출시했습니다. 그 중 대형 코어는 단일 스레드 처리량에 중점을 두고 매트릭스 엔진을 추가해 CPU의 AI 처리 능력을 강화하고 GPU 시장의 일부를 점유할 수 있다. 매트릭스 엔진은 아직 보지 못했습니다. 또 다른 AVX512는 작은 코어에서 취소되었습니다. 큰 코어는 독립적으로 작동할 때만 켤 수 있습니다. 일정에 문제가 있을 수 있습니다. 최신 뉴스는 모두 비활성화된다는 것입니다. AVX512를 사용하려면 Zhiqiang으로 이동해야 합니까?) 또한 더욱 세분화된 전원 관리를 지원합니다. 에너지 효율적인 코어는 멀티 스레드 처리량, 더 깊고 더 많은 포트에 중점을 둡니다.
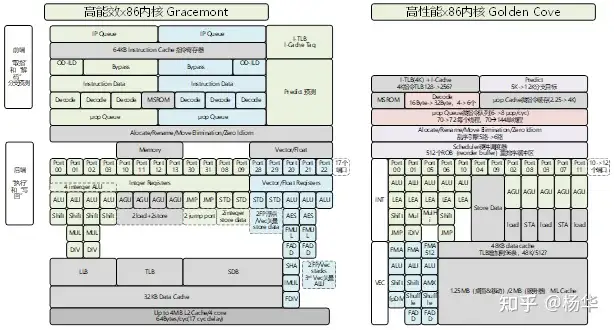
설명하자면, 여기의 에너지 효율 코어(소형 코어)는 전혀 작지 않으며, 코어 성능은 클래식 Skylake와 유사합니다.
이번에도 Alderlake는 일반 CPU에서 Intel이 사용하는 링 버스 구조를 여전히 사용하고 있으며, 4개의 작은 코어 그룹이 노드 역할을 하는데, 이는 Intel에서 시뮬레이션한 링 버스의 최대 노드 수, 즉 10개라고 합니다. 더 많은 노드가 필요합니다. 다른 버스 토폴로지를 고려하십시오.
마이크로아키텍처의 작동 메커니즘을 살펴보면 현재 주류 CPU 마이크로아키텍처는 대략 명령어 가져오기, 명령어 디코딩, 명령어 실행, 메모리 액세스 및 결과 쓰기의 5단계로 나눌 수 있습니다. 일반적으로 프로세서에는 여러 레벨의 파이프라인이 있다고 합니다. 가장 기본적인 것은 5레벨 파이프라인입니다. 그러나 현재 실제 CPU는 이 값보다 큽니다. 주로 빈도가 필요하기 때문에 일부 활동이 강제됩니다. P4의 Willamette 13단 파이프라인, Frequency <2G, Northwoog의 20단 파이프라인, Poseidon의 Prescott 31단 파이프라인(고주파 및 저에너지) 등 여러 비트로 나누어 실행합니다. 인텔의 칩 아키텍처에 대한 자세한 정보를 얻기 어렵기 때문에 이번에는 먼저 기본 개념을 이해하고, 다음에는 오픈소스 CPU를 찾아 그 구성을 자세히 살펴보도록 하겠습니다. 아래에서는 CPU 코어와 관련된 개념에 대해 알아보겠습니다.
1.1.1 프런트엔드
CPU의 프런트 엔드 제어 장치는 명령 전처리를 담당합니다. 명령어 전처리는 일반적으로 가져오기(fetching), 사전 디코딩(predecoding), 융합(fusion), 디코딩(decoding), 분기 예측(branch Prediction), 재배열(rearrangement) 등의 작업으로 구분되며, CPU마다 등급 지정 방법이 다릅니다.
Fetch : 먼저 명령어를 로드합니다. PC 레지스터 값은 주소로 사용되며 I-Cache에서 가져와 명령어 레지스터에 저장됩니다.
PreDecode : 프로그램의 명령 데이터 전체 배치를 첫 번째 명령과 두 번째 명령으로 분할합니다. 명령도 분류하고 표시해야 할 수 있습니다. 미리 디코딩된 명령어는 명령어 큐(Instruction Queue)에 배치됩니다.
디코드 (디코딩이라고도 함): 명령어를 디코딩하고 결과에 따라 레지스터 파일을 읽어 명령어의 소스 피연산자를 얻습니다. CPU가 메모리에 두 숫자를 추가하는 것과 같은 명령을 만나면 세 가지 명령으로 나누어야 합니다: 메모리에서 첫 번째 숫자 로드, 메모리에서 두 번째 숫자 로드, 두 숫자 추가. 일반적으로 원래 명령어를 매크로 연산(Macro-Operations)이라고 하고, 분해된 명령어를 마이크로 연산(μops)이라고 합니다.
명령어 융합(Micro-Fusion/Macro-Fusion) : 하나의 명령어로 대체할 수 있으며, 이러한 처리를 명령어 융합이라고 합니다. 명령어 디코딩 전의 매크로 연산 융합을 Macro-Fusion, 디코딩 후의 마이크로 연산 융합을 Micro-Fusion이라고 합니다.
분기 예측(Branch Prediction) : 예측을 담당하는 모듈을 분기 예측기(Branch Predictor)라고 하며, 분기 명령이 실행되기 전에 어떤 분기가 실행될지 추측하여(과거를 사용하여 미래를 예측) 파이프라인 성능을 향상시킵니다. 분기 예측이 없으면 파이프라인 정지(stalled), 파이프라인 버블링(bubbling) 또는 파이프라인 딸꾹질(hiccup)이 발생합니다. 즉 파이프라인에 실제 효과가 없는 버블이 생성되어 효율성이 떨어집니다. 분기 예측 오류는 쓰기 전 파이프라인 단계를 낭비하게 되며, 파이프라인이 길어질수록 예측 오류에 대한 페널티가 더 커집니다. 일반적으로 정적 분기 예측과 이중 모드 예측으로 구분됩니다. 즉, 포화 카운터를 사용하여 프로그램 방향을 결정합니다.
정적 분기 예측기(Static Prediction) : 분기 명령어 자체에만 의존합니다. 각각 분기를 평가하고 디코딩하는 두 가지 디코딩 주기가 있습니다. ARM11 MPCore 프로세서의 단순 삽입 낮은 대기 시간, 두 번째 수준 분기 예측은 모든 역방향 분기를 사용하는 정적 분기 예측을 사용합니다. 약 65%의 분기 앞에는 완전히 예측할 수 있을 만큼 충분한 비분기 주기가 있습니다.
1.1.2 백엔드 실행 유닛(실행 엔진)
CPU의 실제 컴퓨팅 구성 요소에는 컴퓨팅 구성 요소 주변의 데이터 액세스, 다양한 컴퓨팅 기능 단위 및 스케줄러가 포함됩니다.
데이터 액세스 단위(Load Data/Store Data) : Load Data 단위는 캐시 하위 시스템에서 데이터를 로드하는 역할을 하며, 계산 결과를 캐시 하위 시스템에 다시 쓰는 Store Data 단위가 있습니다.
컴퓨팅 장치(실행) : 산술 논리 장치(ALU)는 이진 정수에 대한 산술 연산이나 비트 연산을 수행할 수 있는 조합 논리 디지털 회로입니다.
컴퓨팅 회로에는 컴퓨터의 중앙 처리 장치(CPU), 그래픽 처리 장치(GPU) 등이 포함되며, 그 중 ALU는 컴퓨팅 회로의 기본 구성 요소이며 단일 CPU, FPU 또는 GPU에는 여러 개의 ALU가 포함될 수 있습니다.
부동 소수점 유닛(FPU) : 부동 소수점 연산을 수행하는 구조체. 일반적으로 회로를 사용하여 구현되며 컴퓨터 칩에 사용됩니다. 이는 정수 산술 장치 이후의 주요 발전입니다. 부동 소수점 산술 장치가 발명되기 전에는 컴퓨터의 부동 소수점 연산이 정수 산술로 시뮬레이션되었으며 효율성이 매우 낮았기 때문입니다. 부동 소수점 계산기에는 오류가 있을 수 있지만 과학 및 공학 계산은 여전히 부동 소수점 계산기에 크게 의존합니다. 그러나 프로그램 설계 중에 정확성 문제를 고려해야 합니다. FPU에서는 부동 소수점 컴퓨팅 기능이 SIMD(Single Instruction Stream Multiple Data) 계산과 통합됩니다.
AGU(Address Generation Unit) : ACU(Address Computing Unit)라고도 하며, CPU가 메인 메모리에 액세스할 수 있도록 주소를 계산하는 중앙 프로세서 내의 실행 장치입니다. 별도의 회로에서 주소 계산을 처리하고 나머지 CPU와 병렬로 실행함으로써 다양한 기계 명령을 실행하는 데 필요한 CPU 사이클 수를 줄여 성능을 향상시킵니다.
TLB(Translation Lookaside Buffer) : 페이지 테이블 캐시, 리디렉션 우회 캐시라고도 하며 CPU의 캐시로 메모리 관리 장치에서 가상 주소를 물리적 주소로 변환하는 속도를 향상시키는 데 사용됩니다. TLB에는 가상 주소를 물리적 주소로 매핑하는 레이블 페이지 테이블 항목을 저장하기 위한 고정된 수의 공간 슬롯이 있습니다. 일반적인 CAM(Content-Addressable Memory)의 경우. 검색 키워드는 가상 메모리 주소이고, 검색 결과는 물리 주소입니다. 요청된 가상 주소가 TLB에 존재하는 경우 CAM은 매우 빠른 일치를 제공하고 결과 물리적 주소를 사용하여 메모리에 액세스할 수 있습니다. 요청한 가상 주소가 TLB에 없으면 가상 및 실제 주소 변환에 레이블 페이지 테이블이 사용되며 레이블 페이지 테이블의 액세스 속도는 TLB보다 훨씬 느립니다.
AES(Advanced Encryption Standard) : Rijndael 암호화라고도 하며 미국 연방 정부에서 채택한 블록 암호화 표준입니다. 이 표준은 원래 DES를 대체하는 데 사용되며 많은 당사자에 의해 분석되었으며 전 세계적으로 널리 사용됩니다. 대칭 키 암호화 알고리즘. AES 암호화 프로세스는 4x4 바이트 매트릭스에서 작동합니다. 이 매트릭스는 "상태"라고도 하며 초기 값은 일반 텍스트 블록입니다(매트릭스의 요소는 일반 텍스트 블록의 바이트입니다). (Rijndae) 암호화 방법은 더 큰 블록을 지원하며 상황에 따라 해당 매트릭스의 "행 수"를 늘릴 수 있습니다.) 암호화 시 AES 암호화 주기의 각 라운드(마지막 라운드 제외). MAC(Multiply Accumulate)는 디지털 신호 프로세서 또는 일부 마이크로프로세서의 특수 작업입니다. 이 연산을 구현하는 하드웨어 회로 장치를 "곱셈기 누산기"라고 합니다. 곱셈의 곱 결과를 누산기 A의 값에 더한 다음 이를 누산기에 저장합니다: a=a+b*c. 많은 연산(예: 컨볼루션 연산, 내적 연산, 행렬 연산, 디지털 필터 연산 및 다항식 계산(값 연산)도 여러 MAC 명령어로 분해하여 연산 효율성을 향상시킬 수 있습니다.
"융합 곱셈-덧셈 연산" / "융합 곱셈-덧셈 연산"(융합 곱셈-덧셈, FMA) 또는 "융합 곱셈-덧셈 연산"(융합 곱셈-누산 FMAC): 융합 곱셈-덧셈 연산의 연산은 기본적으로 곱셈-누산 연산과 동일 부동 소수점 연산도 하나의 명령어로 완료됩니다. 그러나 차이점은 부동 소수점 숫자를 처리할 때 비융합 곱셈과 덧셈의 곱셈-누산 연산은 먼저 bxc의 곱을 완성하고 결과 값을 N 비트로 반올림한 다음 반올림된 결과를 값과 비교한다는 것입니다. 레지스터 a의 덧셈 후 결과를 N 비트로 반올림하고, 융합된 곱셈과 덧셈은 먼저 a+bxc 연산을 완료한 다음 최종 완전한 결과를 얻은 후 N 비트로 반올림합니다. 수치 반올림 횟수의 감소로 인해 이 연산은 연산 결과의 정확성을 향상시킬 수 있을 뿐만 아니라 연산의 효율성과 속도를 향상시킬 수 있습니다. 제품 및 융합 추가 연산은 연산의 성능과 정확성을 크게 향상시킬 수 있습니다: 내적 행렬 곱셈, 다항 방정식 해결(예: Qin Jiushao 알고리즘 등), 함수의 영점을 해결하는 뉴턴 방법.
FMA4 : 2011년 AMD에서 게시하고 불도저 마이크로아키텍처에서 처음 사용된 4차 연산 명령 세트입니다.
FMA3: 삼항 연산 명령어 세트로, AMD가 2012년에 발표하여 파일드라이버 마이크로아키텍처에 처음 사용되었으며, 인텔도 2013년에 하스웰 마이크로아키텍처를 출시하고 FMA3 명령어 세트를 지원하기 시작했습니다.
부동 소수점 나눗셈 명령어(FDIV) : Integer Arithmetic Logic Unit(IntALU)의 경우 정수 덧셈과 뺄셈/이진 연산을 계산합니다. 설명이 필요합니다. 컴퓨터에는 많은 연산이 있습니다.
소수 계산도 Shift 연산을 사용하여 정수 단위로 계산한 다음 소수 자릿수를 계산하여 처리됩니다.
Integer Multiplier (IntMUL) - 정수 곱셈을 담당합니다.
정수 나누기를 담당하는 Integer Divider (IntDIV)
정수 벡터 ALU(Int VectALU) , 벡터는 공간 좌표 + 값(x, y, z, 값)과 유사한 데이터 집합을 의미하며, 여기서 x, y, z 및 값은 모두 정수입니다. 정수와 마찬가지로 덧셈과 뺄셈/이진 정수 벡터 ALU 외에도 정수 벡터 곱셈기와 나눗셈기(Int Vect MUL, Int Vect DIV)도 있습니다.
부동 소수점 벡터 덧셈 및 곱셈 융합 장치(Fused Multiply-Add, FP FMA) , 부동 소수점 벡터 + 덧셈 및 곱셈 융합, 계수 값은 별도의 곱셈 또는 뺄셈 및 기타 연산을 구현합니다.
부동 소수점 나눗셈 장치(FP DIV) : 부동 소수점 나눗셈을 계산하고 제곱근, 로그 등과 같은 일부 일반적인 함수도 계산할 수 있습니다.
다양한 점프 명령을 담당하는 분기 처리(Branch);
스케줄러(Scheduler) 서로 다른 컴퓨팅 장치에 대해 CPU에는 해당 컴퓨팅 장치에 서로 다른 컴퓨팅 명령을 할당하는 스케줄러가 필요합니다. 포트에 해당하는 다른 연산자.
레지스터 파일(Register File) 하나의 데이터가 서로 다른 컴퓨팅 유닛에 의해 여러 번 처리될 필요가 있을 수 있으며, 컴퓨팅 유닛에 따라 여러 그룹으로 나누어지며, 여러 레지스터의 조합을 레지스터 파일이라고 합니다. 각 컴퓨팅 장치는 특정 이름을 가진 레지스터의 데이터만 처리할 수 있으므로 스케줄러는 종종 레지스터에 할당, 이름 바꾸기, 종료 및 기타 작업을 수행해야 합니다.
캐시 아키텍처와 프런트엔드 및 실행 장치에는 메모리를 가속화하고 CPU의 컴퓨팅 장치를 최대한 가득 채우는 데 사용되는 캐시 아키텍처가 장착되어 있습니다. 자세한 내용은 캐시 아키텍처 장의 관련 소개를 참조하세요.
이번 글은 주로 인텔 12세대 아키텍처의 앨더레이크(Alderlake)를 살펴보며 CPU를 구성하는 마법 같은 것들을 이끌어내는 데 초점을 맞췄다. 이 글이 기본이고, 나중에 더 많은 정보가 포함된 오픈소스 예제를 찾아 칩 아키텍처에서 이러한 개념을 함께 연결해 보겠습니다. 나중에 뵙겠습니다.
세상에 마법은 없지만 우리는 아직 그것을 이해하지 못하기 때문에 마치 마법이 있는 것처럼 보입니다.