컴퓨터/노트북/인터넷
IT 컴퓨터 기기를 좋아하는 사람들의 모임방
Ice Lake는 Intel 차세대 플랫폼의 아키텍처 코드 명으로, Taipei Computer Show에서 시연 된 후 마침내 미스터리의 베일을 벗겼습니다. 얼마 전 인텔의 내부 2 분기 재무 보고서 회의에서 CEO는 Ice Lake 프로세서가 공식적으로 OEM에 배송되었다고 발표했으며 Dell은 새로운 Ice Lake 프로세서로 XPS 13을 한 달 이상 연기하기 위해 신속하게 움직였습니다. 7390은 주문을 받기 위해 신속하게 선반에 있으며 곧 배송 될 예정입니다. 즉, Intel의 1 세대 양산 10nm 제품 (Cannon Lake의 유일한 10nm i3 제외)이 마침내 시장에 출시 될 것입니다. 이때 편집자는 현재 Ice Lake 아키텍처를 편집하고 편집했습니다. 관련 분석 기사를 통해 그이면의 개선 사항을 살펴보십시오.
인텔이 지난번 데스크탑 프로세서의 아키텍처를 업데이트 한 지 거의 5 년이 지났습니다. Skylake는 매우 성공적인 아키텍처 세대이며 P6 이후 인텔에서 가장 오래 실행되는 프로세서 세대 일 수도 있습니다. 인텔을 지원하는 아키텍처는 여전히 주류 및 서버 시장에서 우위를 점하고 있습니다.
우선, Ice Lake가 전체 프로세서 아키텍처의 코드 이름이고 현재 Intel 프로세서 아키텍처에는 Uncore 부분의 코어, GPU 및 기타 IO 장치가 포함되어 있음을 명확히해야합니다. 따라서이 기사는 CPU의 핵심 마이크로 아키텍처만을위한 것이 아닙니다. 분석 용이지만 전체 아키텍처 용입니다.
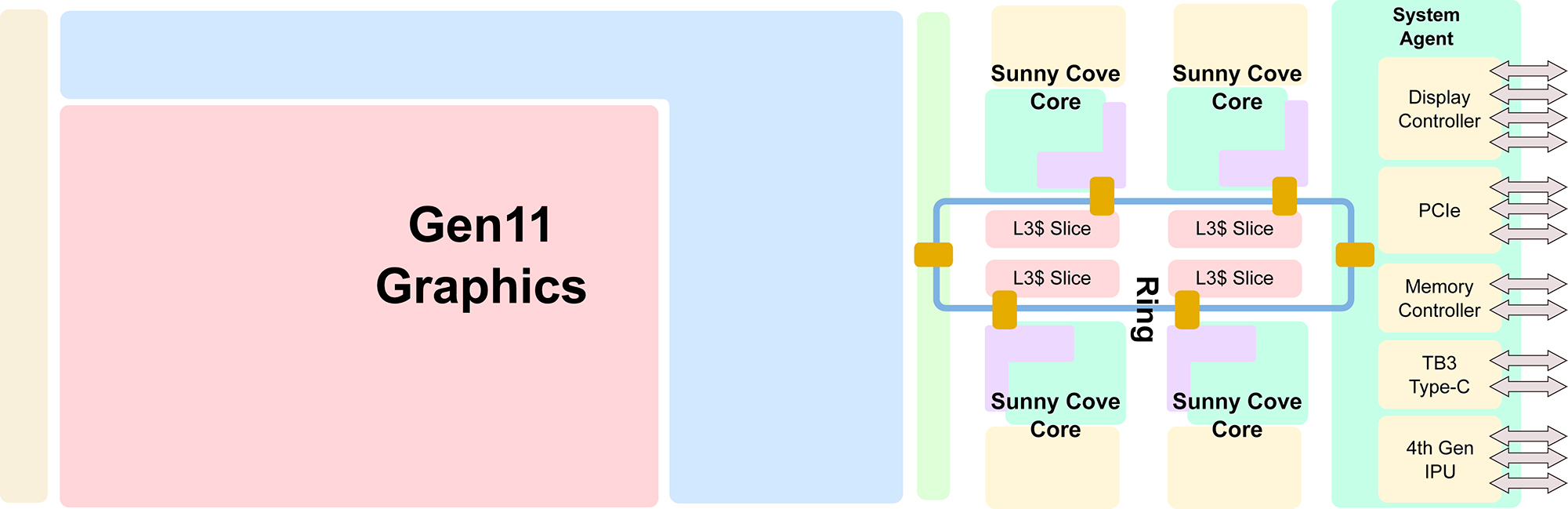
Ice Lake 프로세서 구조 다이어그램
Sunny Cove 코어 마이크로 아키텍처 : IPC가 평균 18 % 증가
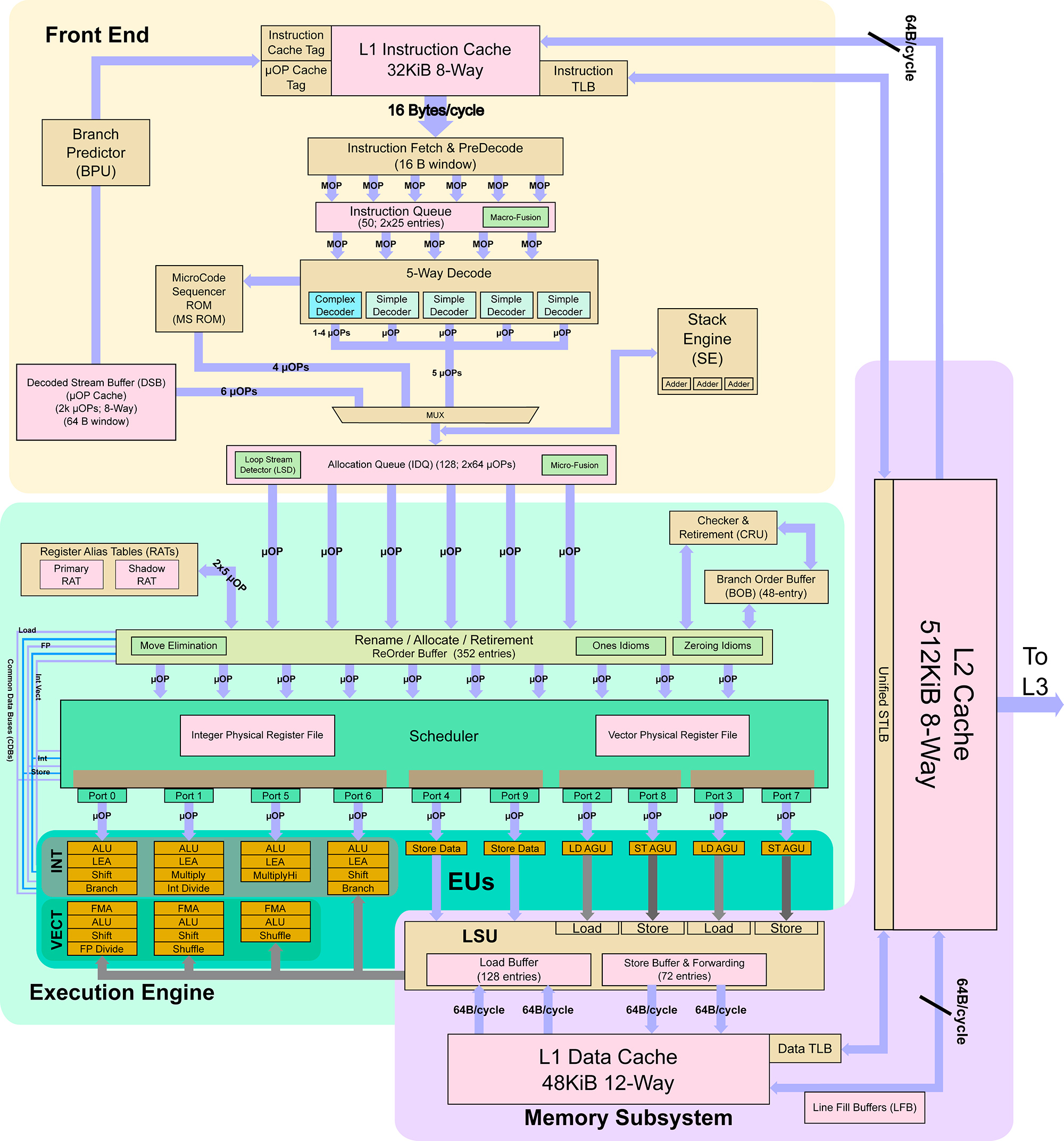
Sunny Cove 커널 구조 다이어그램
완충 구역 : 증가, 증가, 증가
x86 프로세서의 커널은 간단히 프런트 엔드 부분과 백 엔드 실행 부분의 두 부분으로 나눌 수 있습니다. 프런트 엔드 부분은 주로 "가져 오기 및 디코딩"작업을 완료합니다. 백 엔드는 주로 특정 명령 실행 단위입니다. 버퍼는 디코딩 및 융합 된 마이크로 명령어를 저장하는 데 사용됩니다. 인텔은 효율성을 높이기 위해 커널에 "마이크로 명령어 융합"기술을 오랫동안 도입 해 왔습니다. 융합 된 마이크로 명령어는 버퍼에 들어간 다음 특정 실행을 위해 백엔드 실행 부분에 할당됩니다. Intel은 현재 프로그램의 병목 현상이 메모리 액세스 및 프런트 엔드 명령 전달에 있다고 생각합니다. Sunny Cove의 프런트 엔드 개선 사항은이 개념을 반영하므로 이번에는 버퍼가 많이 확장되었습니다.
Intel은 352 개의 microinstruction을 수용 할 수 있도록 ReOrder Buffer (ReOrder Buffer, 비 순차적 실행 후 실행될 microinstructions에 주로 사용됨)의 크기를 조정 한 것을 알 수 있습니다. 128 / 57 % 증가한 반면 Haswell에서 Skylake까지 32 % 증가했습니다. 또한 메모리 액세스도 많이 개선되었습니다 .Load queue는 56 개, Store queue는 16 개 증가하여 Haswell에서 Skylake로 변경 한 것보다 훨씬 더 많습니다.
| Haswell | Skylake | 아이스 레이크 | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 단일 코어 레벨 1 데이터 캐시 크기 | 32KB | 32KB | 48KB | |||||||||||||||||||||||||||||
| 단일 코어 레벨 1 명령어 캐시 크기 | 32KB | 32KB | 32KB | |||||||||||||||||||||||||||||
| 단일 코어 보조 캐시 크기 | 256KB | 256KB | 512KB | |||||||||||||||||||||||||||||
| 매크로 캐시 | 1.5K μOPS | 1.5K μOPS | 2.25K μOPS | |||||||||||||||||||||||||||||
| 슈퍼 네트워크 제작 | ||||||||||||||||||||||||||||||||
캐시를 다시 살펴보면 새 커널은 마침내 32KB에서 48KB로 수만 년 동안 변경되지 않은 레벨 1 데이터 캐시를 추가했지만 12KB 만 증가했지만 32KB 레벨 1 명령 캐시 + 32KB 레벨 1 데이터 캐시를 알아야합니다. 이 디자인은 Core 시리즈의 1 세대 아키텍처 인 Core 마이크로 아키텍처부터 사용되어 지금까지 사용되었으며 1 단계 데이터 캐시의 대역폭도 증가했습니다. 각 코어에 연결된 L2 캐시는 512KB 크기로 직접 두 배가되었습니다. Nehalem 아키텍처가 각 코어에 L2 캐시를 구축하고 별도의 공유 L3 캐시를 설정했기 때문에 커널 캐시의 가장 큰 변화이기도합니다. .

Skylake 및 Sunny Cove 커널 아키텍처 비교 다이어그램, 왼쪽의 Skylake, 오른쪽의 Sunny Cove
프런트 엔드 부분의 개선은 주로 프리 페처 및 분기 예측기의 성능을 개선하고주기 당 5 (6) 명령의 발행을 충족 할 수 있도록 마이크로 명령 캐시의 크기를 늘리기위한 것입니다.
백엔드 : 더 넓게

Skylake 위로, Icelake로 이동, Port에주의
백엔드도 많이 변경되었습니다. Sunny Cove는 Skylake보다 실행 포트가 두 개 더 많아 최대 10 개에 이릅니다. 그리고 포트의 목적은 더욱 정교 해지고 주소를 읽고 저장하는 전용 포트가 있으며 데이터 액세스 전용 포트는 2 개입니다.
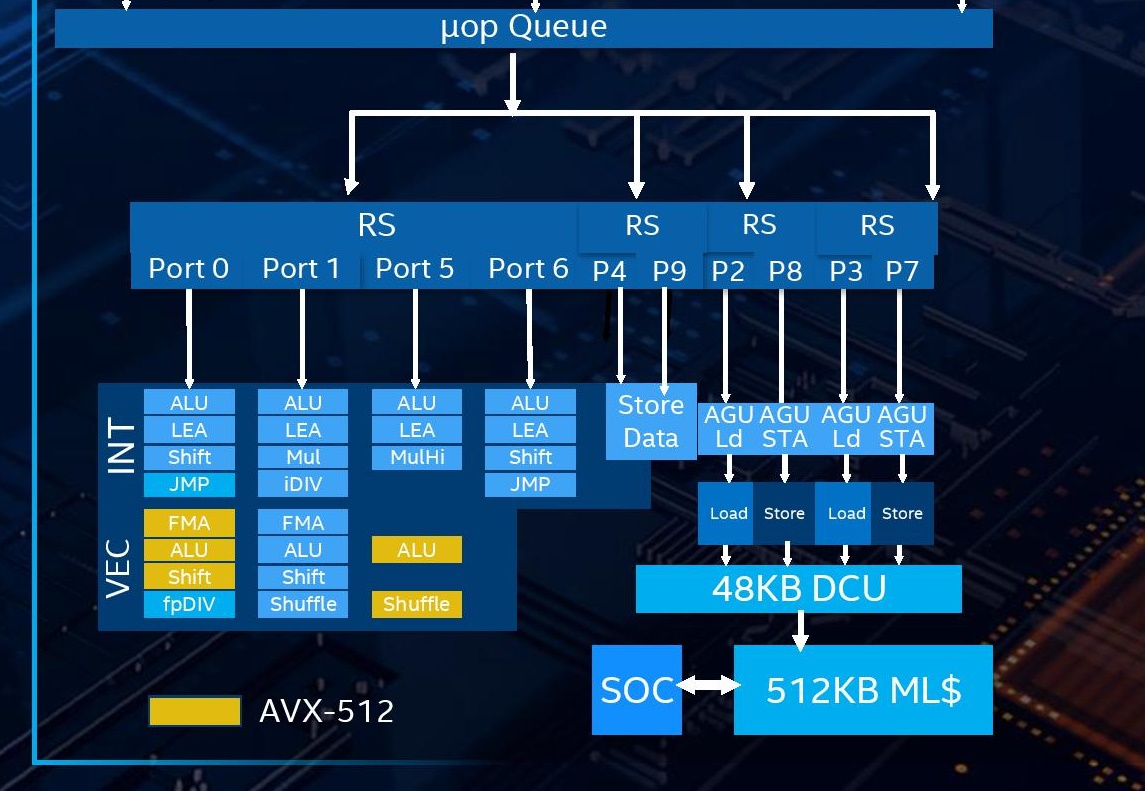 이후 실행 유닛에 써니 코브는 AVX -512 명령어 를 지원하는 유닛을 추가했고 , 실제로이 유형의 유닛은 Skylake-Server에 추가되었으며 동시에 Cannon Lake에 추가 된 하드웨어 정수 분할기 iDIV도 도입했습니다. 곱셈 명령 처리를위한 새로운 MulHi 장치도 추가되었습니다.
이후 실행 유닛에 써니 코브는 AVX -512 명령어 를 지원하는 유닛을 추가했고 , 실제로이 유형의 유닛은 Skylake-Server에 추가되었으며 동시에 Cannon Lake에 추가 된 하드웨어 정수 분할기 iDIV도 도입했습니다. 곱셈 명령 처리를위한 새로운 MulHi 장치도 추가되었습니다.
AVX-512 컴퓨팅 장치의 도입으로 Sunny Cove 코어는 한 번에 하나의 512 비트 명령 또는 두 개의 256 비트 명령을 처리 할 수 있습니다.
코어 상호 연결 측면에서 데스크톱 수준의 Ice Lake는 링 버스 설계 인 Ringbus를 계속 사용하고 서버 측은 Skylake-Server Mesh 버스 설계를 계속할 것입니다.
명령어 세트 및 AI 가속
指令集随着新单元的加入也同时进行了扩充,在加密解密、AI加速、通用计算、特定计算等方面都新加入了不少指令,尤其是AVX-512指令集。
对于近几年大热门的人工智能,Intel一方面在Uncore部分加入了自家的“高斯网络加速器(Gaussian Network Accelerator)”这样类似于手机SoC上面常见的AI硬件加速电路,还通过引入AVX512VNNI指令集,使用AVX-512单元来进行AI相关的加速计算,Intel将这种加速称为"DL(Deep Learning) Boost"。这是一种很聪明的取巧办法,专用计算单元的引入可以保证一定的加速性能,而新指令集的加入同时也可以更加充分地利用上新的CPU特性。
加密解密指令集上面的改动诸如AES的吞吐量加大、加入新的针对SHA算法的一系列指令等,总之在编译器进行适当优化的前提下,Ice Lake的加密解密性能是比Skylake强不少的。
小结
简单归纳一下Sunny Cove微架构的改进点:
-
改进了预取器与分支预测器的性能
-
一级数据缓存增大50%
-
一级缓存存储带宽增大100%
-
二级缓存增大100%
-
微指令缓存增大50%
-
每周期能够加进乱序重排缓冲区的微指令多了25%
-
乱序重排缓冲区大了57%
-
后端执行端口多了25%
-
支持AVX-512等新指令集
综合以上的改进,Sunny Cove相对于Skylake在IPC上面取得了平均18%的进步,而对于Broadwell或者说Haswell,则是有47%的进步幅度,在针对AVX-512进行优化过的测试中,最高可以比上代移动低压处理器快2~2.5倍。在摩尔定律前进缓慢的今天,这个数字已经非常高了。
주제 외에도 AVX-512, 관련 명령 세트 변경 및 캐시 대역폭 증가 등과 같은 Cannon Lake에서 이미 많은 개선이 이루어졌으며 일부 변경 사항은 AI 가속과 같은 Skylake-Server 아키텍처에서 분산되었습니다. 명령 세트는 실제로 서버 측 프로세서에 나타났습니다. 그러나 Cannon Lake는 실제로 Intel이 포기했기 때문에 Cannon Lake의 개선 사항을 계승 한 Sunny Cove 커널 아키텍처는 Skylake에 비해 평균 18 %의 IPC 향상을 얻을 수 있습니다. 모든 것이 정상이면 Intel의 10nm는 지연되지 않으며 Ice Lake는 Cannon이어야합니다. 차세대 Lake는 그다지 개선되지 않았습니다.
11 세대 그래픽 아키텍처
Ice Lake의 핵심 디스플레이는 처음으로 1TFlops의 컴퓨팅 성능에 도달했으며 많은 개선 사항으로 설명 할 수있는 많은 기능을 추가했습니다. 인텔은이 세대의 핵 그래픽의 성능을 설명하기 위해 "가장 강력한 버전"을 사용했습니다. 어떻게 그랬습니까?

10nm 공정, 격렬한 스태킹 스케일
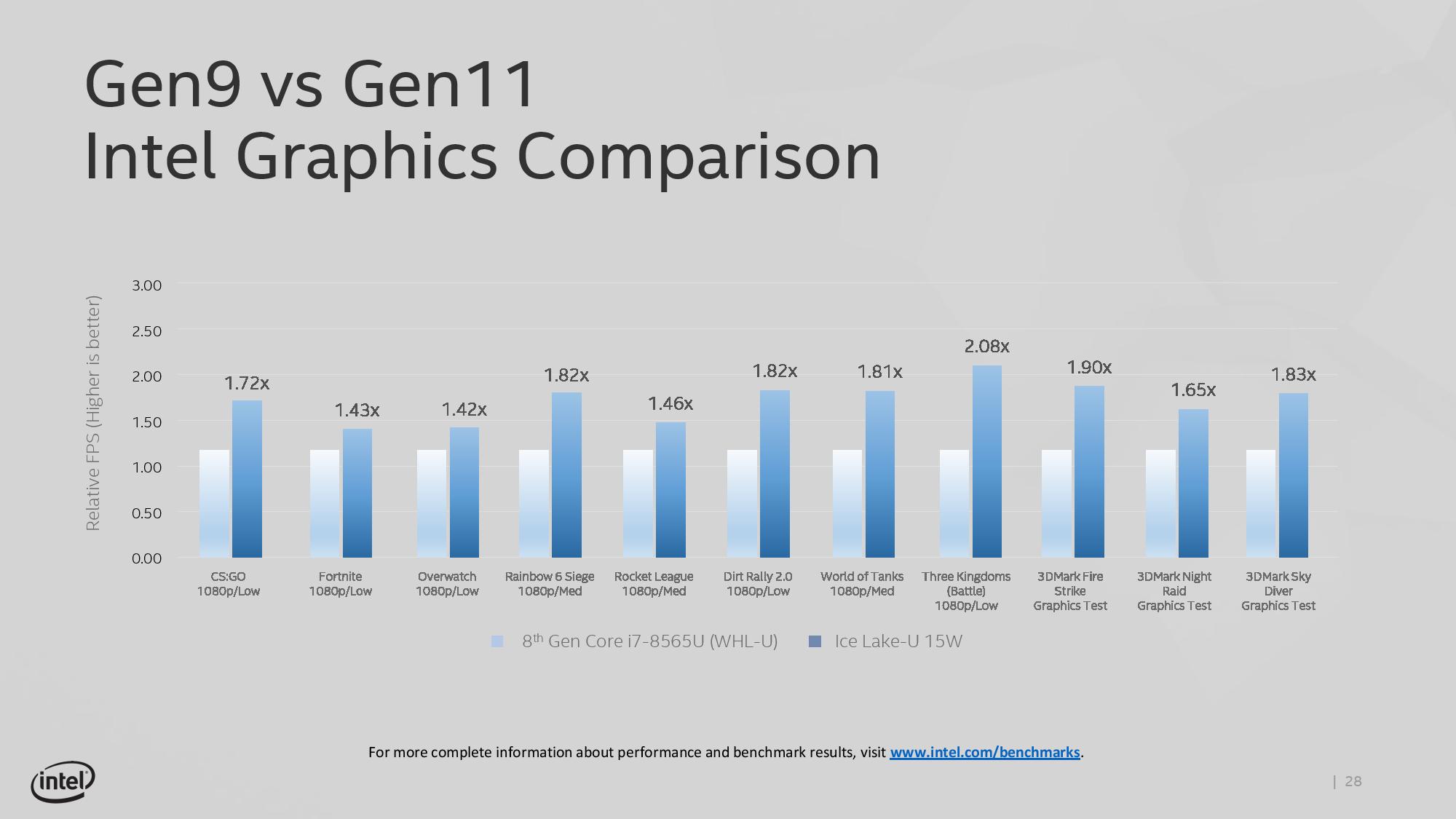
인텔의 10nm 공정은 트랜지스터 밀도를 크게 향상 시켰습니다. 14nm 시대에는 최대 48 세트의 EU 원자력 디스플레이 (GT4e는 고려하지 않음)를 장착했습니다. 아이스 레이크에서 직접 1.5 배 증가했으며 최대 64 세트까지 EU에 도달 할 수 있습니다. 그리고 주파수는 낮지 않고 최고는 1100MHz까지 달릴 수있어 이전보다 50MHz에 불과하며 현재 핵 디스플레이의 전체 FP32 계산은 1.15TFlops에 도달했습니다. 이를 고려하여 8 세대 코어 프로세서의 9 세대 코어 디스플레이에 비해 인텔은 공식적으로 약 1.8 배의 평균 프레임 속도를 제공한다고 공식적으로 주장합니다.
 10 세대가 어디로 갔는지 물어봐야 겠죠? 사실, 그것은 여전히 중단 된 캐논 레이크에 있고 유일한 핵심 디스플레이는 여전히 차단되어 있습니다.
10 세대가 어디로 갔는지 물어봐야 겠죠? 사실, 그것은 여전히 중단 된 캐논 레이크에 있고 유일한 핵심 디스플레이는 여전히 차단되어 있습니다.
현재 Ice Lake 프로세서의 모바일 저전압 버전에서 Intel은 각각 32/48/64 EU 그룹을 포함하는 G1, G4 및 G7 코어 디스플레이의 총 세 가지 구성을 제공하고 저가형 G1은 여전히 "UHD"로 이름이 지정되며 G4 G7과 G7은 모두 "Iris Plus"브랜드로 등장했습니다.
프로세스 개선을 통해 EU 수를 쌓는 것 외에도 내부 구조의 최적화도 중요합니다.
내부 구조 최적화

9 세대 원자력 디스플레이와의 비교표는 그림에 나와 있습니다. 출처 : Weekend talk, Icelake CPU assistant, Gen11 원자력 디스플레이 소개
먼저 단일 슬라이스에 포함 된 하위 슬라이스를 늘려 배율을 확장하여주기 당 계산 수를 늘립니다.
두 번째는 캐시 시스템에 소란을 일으키고 3 단계 캐시의 용량을 확장하는 것입니다 .Intel은 EU의 3 단계 캐시가 3MB이고 로컬 공유 메모리가 0.5MB라고 발표했습니다. 더 높은 메모리 대역폭을 사용할 수있는 프로세서의 메모리 컨트롤러를 통한 업그레이드도 있습니다.
새로운 인터페이스 버전 및 향상된 하드웨어 코딩 회로
지난달 에디터에게 가장 불편한 점 중 하나는 1440p, 144Hz 주사율 모니터를 구입하는 것이 었습니다. HDMI를 사용하여 노트북에 연결할 때 최대 출력은 1440p에서 60Hz에 불과합니다. 그 이유는 구 9 일이었습니다. 코어 디스플레이에서 지원하는 HDMI 버전은 최대 1.4까지만 가능하며 4K @ 30Hz 출력 만 제공 할 수 있으며 최대는 1080p에서 120Hz이며 내 노트북은 USB-C 또는 DP 출력을 제공하지 않습니다.
그리고 Ice Lake는 마침내 HDMI 2.0b 및 DP 1.4 HBR3을 지원하여이 문제를 해결했습니다. 어쨌든이 둘은 말할 것도없이 가장 높은 해상도와 프레임 속도 증가는 HDR도 지원할 수 있습니다.
또한 비디오 하드웨어 인코딩 부분, 즉 Intel QuickSync 기능에서 사용하는 독립 하드웨어 회로에서 새로운 코어 디스플레이도 상대적으로 크게 개선되었습니다. 이제 두 개의 HEVC 10 비트 인코딩을 동시에 지원합니다. YUV444의 경우 최대 2 개까지 지원합니다. 4K60 프레임 비디오 스트림 또는 YUV422 8K30 프레임 비디오 스트림.
가변 율 음영 (VRS)
VRS의 정식 명칭은 GPU가 영상 영역의 중요도에 따라 음영 정확도를 조정할 수있는 새로운 기술인 Variable Rate Shading입니다. 특정 효과는 이전 뉴스에서 소개되었습니다. 살펴볼 수 있습니다. VRS 가변 속도 음영 기술을 비교해 보겠습니다 . 3DMark는이 기술의 벤치마킹 에 대한 기사에 이미지 비교를 추가 할 것 입니다.
 VRS는 중요하지 않은 화면에 일정량의 GPU 리소스를 절약 할 수 있으므로 GPU 리소스의이 부분이 화면의 더 중요한 부분의 렌더링에 참여할 수 있도록하여 전체 프레임 수를 늘릴 수 있습니다. 현재 NVIDIA는 Turing 코어에 관련 지원을 추가했습니다. 인텔은 11 세대 핵 디스플레이에서이 기능을 제공하면서 뒤처지지 않았으며,이 기능을 언리얼 엔진에 추가하기 위해 에픽과 협력 할 것이라고 발표했습니다. 현재 문명 VI는이 기술을 지원했으며 인텔에 따르면 최대 프레임 수가 30 % 증가했습니다.
VRS는 중요하지 않은 화면에 일정량의 GPU 리소스를 절약 할 수 있으므로 GPU 리소스의이 부분이 화면의 더 중요한 부분의 렌더링에 참여할 수 있도록하여 전체 프레임 수를 늘릴 수 있습니다. 현재 NVIDIA는 Turing 코어에 관련 지원을 추가했습니다. 인텔은 11 세대 핵 디스플레이에서이 기능을 제공하면서 뒤처지지 않았으며,이 기능을 언리얼 엔진에 추가하기 위해 에픽과 협력 할 것이라고 발표했습니다. 현재 문명 VI는이 기술을 지원했으며 인텔에 따르면 최대 프레임 수가 30 % 증가했습니다.
요약
GPU 부분의 개선은 주로 규모의 큰 증가에 기인합니다. 아키텍처는 주로 캐시 시스템을 개선하기위한 작은 변화이지만 11 세대 원자력 디스플레이의 진전은 매우 분명합니다.
 어쩌면 미래에는 1080p의 낮은 화질에서 핵 디스플레이는 더 이상 맛이없고 30 프레임으로 게임을 할 수있을 것입니다.
어쩌면 미래에는 1080p의 낮은 화질에서 핵 디스플레이는 더 이상 맛이없고 30 프레임으로 게임을 할 수있을 것입니다.
Uncore 섹션
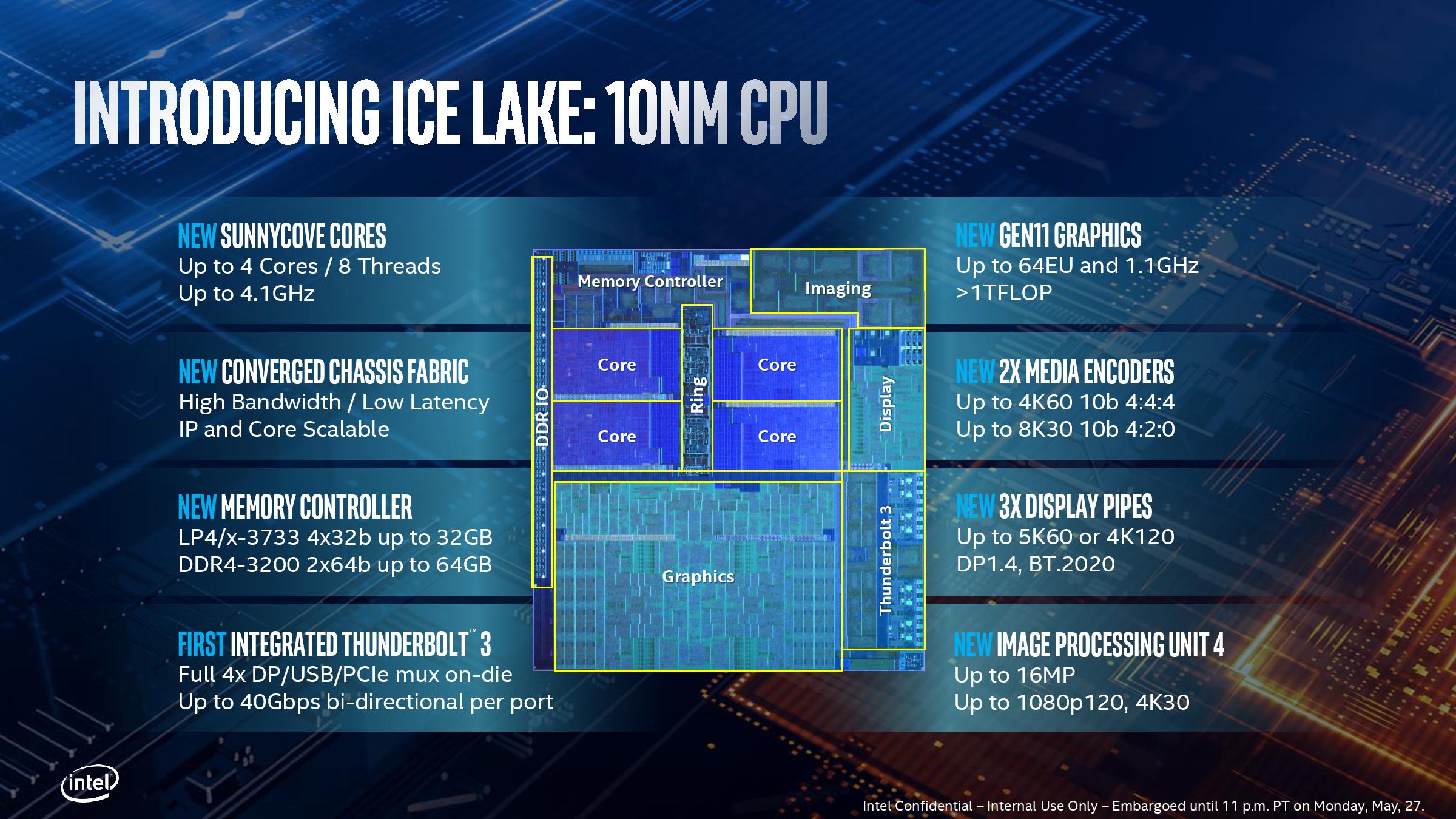
Uncore 부분은 커널과 GPU를 제외한 프로세서의 다른 부분을 의미합니다. 상단 구조도에서 시스템 에이전트의 부분입니다. Intel이 메모리 컨트롤러와 PCI-E 컨트롤러를 Nehalem의 CPU로 옮긴 이후로 큰 변화 였지만 이번에는 인텔이 새로운 기능을 추가하고 많은 오래된 구성 요소를 업그레이드했습니다.
Thunderblot 3
사람들이 Thunderblot (이하 TB라고 함) 장치를 사용하지 못하게 한 이유 중 하나는이 인터페이스를 사용하는 데 드는 비용이 약간 더 높았 기 때문입니다 .TB3가 USB Type-C 인터페이스 형태로 나타나기 시작했을 때 실제로 사용률이 높았지만 다른 장애물 중 하나는 TB를 사용하려면 마더 보드에 추가 칩이 필요하며이 제어 칩은 저렴하지 않습니다. 마지막으로 Ice Lake에서 Intel은 TB 컨트롤러를 프로세서에 통합했으며 더 이상 프로세서가 제공하는 PCI-E 버스를 점유하지 않거나 PCH와 함께 이미 붐비는 DMI 3.0 버스를 짜지 않습니다. 그것은 링 버스에서 그 자리를 차지합니다.
 그리고 Intel은 한 번에 4 개의 TB3 포트를 제공했으며, 각 포트 는 PCI-E 3.0 x4의 전체 사양입니다. 즉, Ice Lake 프로세서에는 실제로 32 개의 PCI-E 3.0 채널이 있지만 이들 중 절반은 TB3 형태로 제공되며, 물론 이러한 인터페이스는 USB 모드를 지원하며 USB 2.0 상태에서 실행시 통신을 위해 PCH를 우회합니다.
그리고 Intel은 한 번에 4 개의 TB3 포트를 제공했으며, 각 포트 는 PCI-E 3.0 x4의 전체 사양입니다. 즉, Ice Lake 프로세서에는 실제로 32 개의 PCI-E 3.0 채널이 있지만 이들 중 절반은 TB3 형태로 제공되며, 물론 이러한 인터페이스는 USB 모드를 지원하며 USB 2.0 상태에서 실행시 통신을 위해 PCH를 우회합니다.
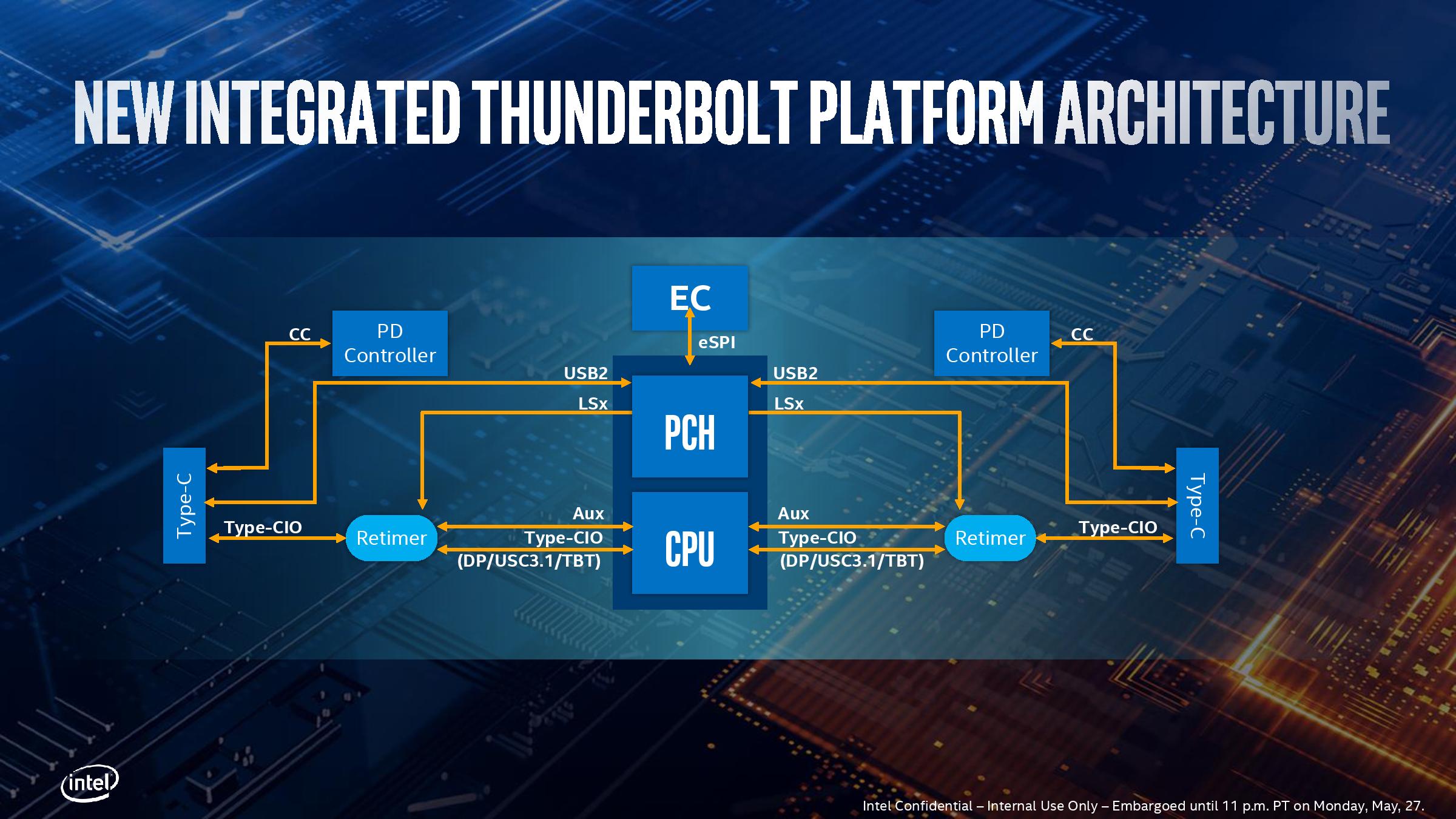 물론 모든 제조업체가 4 개의 TB3 인터페이스를 충분히 제공하는 것은 아닙니다. 특정 구성은 OEM 제조업체에 따라 다릅니다. 결국 USB PD에서 요구하는 독립 IC와 같은 다른 지원 칩은 비용을 증가시키고 TB 인터페이스는 추가로 필요합니다. 리 타이머 칩이지만 인텔은 필요한 리 타이머를 절반으로 줄였으며 2 개의 TB3에 하나의 리 타이머 만 필요합니다.
물론 모든 제조업체가 4 개의 TB3 인터페이스를 충분히 제공하는 것은 아닙니다. 특정 구성은 OEM 제조업체에 따라 다릅니다. 결국 USB PD에서 요구하는 독립 IC와 같은 다른 지원 칩은 비용을 증가시키고 TB 인터페이스는 추가로 필요합니다. 리 타이머 칩이지만 인텔은 필요한 리 타이머를 절반으로 줄였으며 2 개의 TB3에 하나의 리 타이머 만 필요합니다.
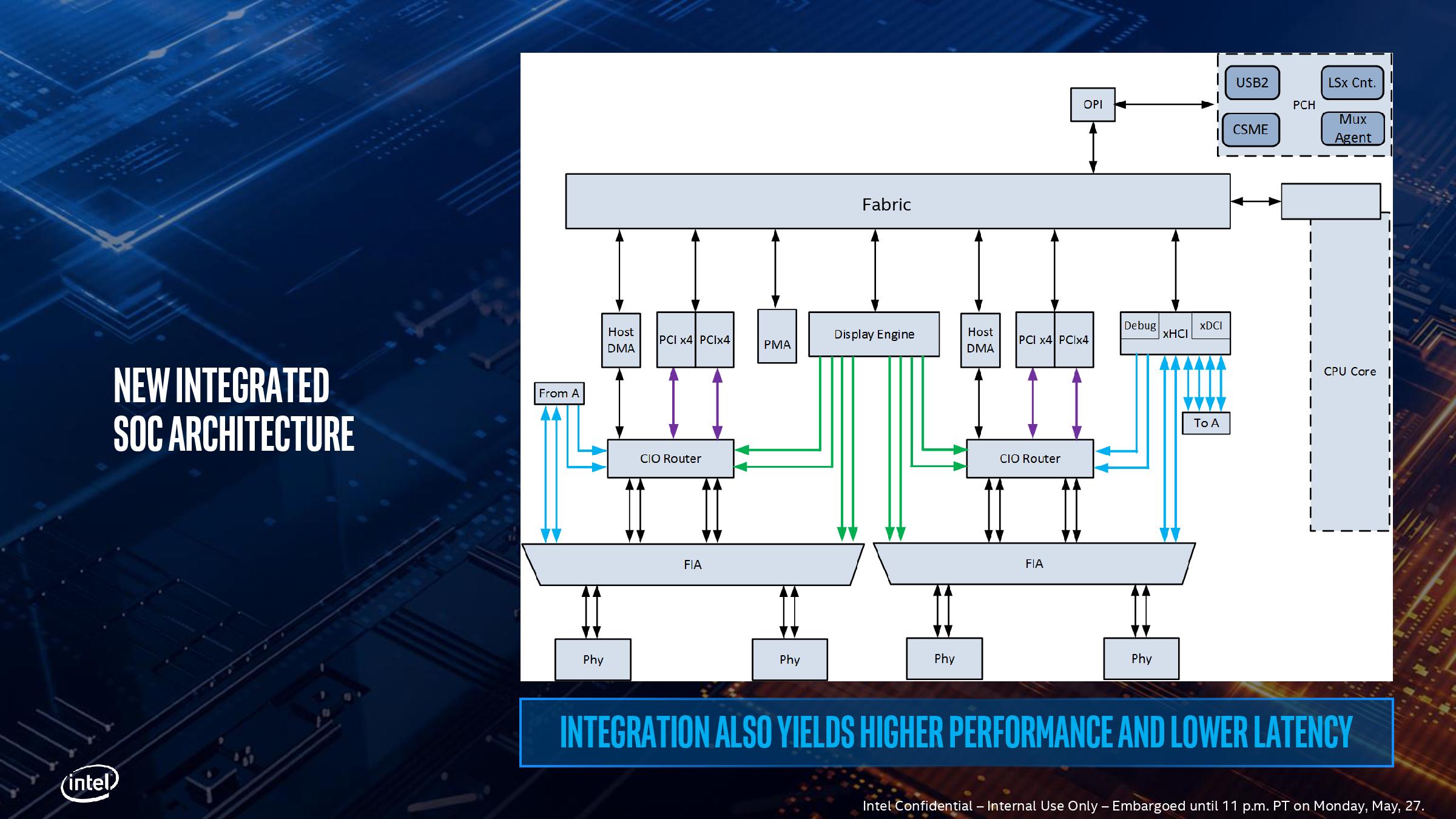 그러나 TB 컨트롤러를 CPU에 통합하면 전체 시스템 에이전트의 IO 부분도 더 복잡해집니다. 위는 상세한 개략도입니다. Type-CIO 라우터 (그림에서 CIO 라우터라고 함)에는 두 개의 PCI-E가 있습니다. 3.0 x4는 CPU에 연결되고 CPU 내부의 디스플레이 제어 엔진 (그림의 디스플레이 엔진)도이 Type-CIO 라우터에 연결되어 Type-C 인터페이스의 상태를 제어하고 전송 된 신호를 결정합니다. 동시에 USB의 xHCI를 Type-CIO에 연결하고 전체 메모리 통합을 관리해야합니다.
그러나 TB 컨트롤러를 CPU에 통합하면 전체 시스템 에이전트의 IO 부분도 더 복잡해집니다. 위는 상세한 개략도입니다. Type-CIO 라우터 (그림에서 CIO 라우터라고 함)에는 두 개의 PCI-E가 있습니다. 3.0 x4는 CPU에 연결되고 CPU 내부의 디스플레이 제어 엔진 (그림의 디스플레이 엔진)도이 Type-CIO 라우터에 연결되어 Type-C 인터페이스의 상태를 제어하고 전송 된 신호를 결정합니다. 동시에 USB의 xHCI를 Type-CIO에 연결하고 전체 메모리 통합을 관리해야합니다.
복잡한 구조로 인해 전체적인 지연이 증가합니다. 인텔은 전원 제어에 원인을주었습니다. 원래의 별도 칩은 전원 상태를 관리하기 쉽지만 통합 후에는 각 부품마다 관리해야하는 자체 전원 상태가 있습니다. 전체적인 지연을 증가시키는보다 정제 된 전원 관리 시스템. 그러나보다 정제 된 전력 관리는 에너지 소비 효율을 향상시킬 수 있다는 점에서 여전히 유익합니다. 인텔은 TB3 인터페이스와 링크 레이어가있는 완전로드 된 칩이 300mW의 전력을 사용하고 4 개는 1.2W에 불과하다고 말했습니다.
인텔은 이미 USB4와의 호환성을 훌륭하게 수행했지만 USB4가 아직 초안 단계에 있다는 점을 고려할 때 향후 개정판에서 호환성을 배제하지는 않습니다. 그러나 현재 아키텍처 분석은 Ice Lake의 모바일 버전에만 해당되며 인텔이 데스크탑 수준의 Ice Lake에도 내부 TB 컨트롤러를 보유하고 있다는 점을 배제하지 않습니다.
주제를 제외하고 TB3는 Cannon Lake에서 사용할 수 있다고 말했지만 죽었습니다.
메모리 컨트롤러
이제 메모리 컨트롤러는 기본적으로 DDR4 3200 / LPDDR4X 3733 메모리를 지원합니다. 원래 Skylake의 메모리 컨트롤러는 최대 8 세대 Coffee Lake 이후 인 DDR4 2666 만 지원할 수 있습니다. DDR4 메모리의 개발과 함께 무음 주파수의 3,000 개의 메모리 모듈도 등장하기 시작했으며, 메모리 컨트롤러가 DDR4 3200을 직접 지원하는 것은 좋은 일입니다. 그리고 프로세서 코어 수가 증가함에 따라 메모리 대역폭이 점차 프로세서 성능에 병목 현상이되고 있습니다. 테스트에서 메모리 대역폭이 게임 성능에 미치는 영향은 매우 분명합니다.
이전에 인텔의 모바일 저전압 플랫폼은 LP DDR3 만 메모리로 사용할 수 있었으며 LPDDR4 / X를 지원하는 이점 중 하나는 특히 이번에는 그래픽 성능의 더 큰 개선을 위해 더 낮은 전력 소비로 더 강력한 성능을 제공 할 수 있다는 것입니다. Ice Lake의 경우 메모리 대역폭이 GPU의 실제 성능에 직접적인 영향을 미치기 때문에 실제적으로 매우 중요합니다.
GNA

앞서 커널의 AI 가속에 대해 이야기 할 때 Uncore 부분에 AI 용 하드웨어 가속 장치 인 GNA가 추가되었다고 언급되었습니다. 현재로서는 잘 모릅니다. 특정 이름에도 두 가지 버전이 있습니다. 인텔은 공식적으로 Windows를 대상으로합니다. Machine Learning 소개 페이지 에서 전체 이름은 Gaussian Network Accelerator이며 Ice Lake 아키텍처를 소개하는 많은 기사에서 이름은 Gaussian Neural Accelerator가되었습니다.
유닛의 전력 소모가 매우 낮고 나머지 SoC가 꺼져도 계속 작동하는 것으로 알려져 있으며 안정적인 AI 가속 성능을 제공하는 것을 목표로하고 있으며, 적용 시나리오는 음성 인식 등이다.
이미지 처리 장치
Ice Lake의 이미지 처리 장치가 4 세대로 업그레이드되었습니다. 예, 아마도 Intel CPU의 이미지 처리 장치에 대해 들어 보지 못했을 것입니다.하지만 Skylake 이후로 사용되었지만 DSP (디지털 신호 처리기) 범주에 속하는 모바일 듀얼 코어 모델이 있으며 장치의 카메라에 이미지 처리 기능을 제공합니다.
Ice Lake上的IPU可以提供4K@30fps的视频拍摄能力,还有更好的硬件降噪能力,支持更多的相机,还支持将两个不同的相机比如一个抓IR信息一个抓RGB信息的两个相机模拟成一个设备来看待。
Intel方面称,他们正在向软件开放更多的IPU寄存器,以向应用提供更好的便利性,并且提供了对机器学习的支持。另外值得一提的是,Intel将之前PCH上集成的MIPI接口转移到了CPU上,未来可以用于接驳AI加速设备。
小结
PCH改进
目前的Ice Lake平台上PCH和CPU是封装在同一块基板上的,PCH的提升同样是Ice Lake整个平台的提升。同样的,Ice Lake CPU通过DMI 3.0 x4总线与PCH相连,提供的带宽等同于PCI-E 3.0 x4。
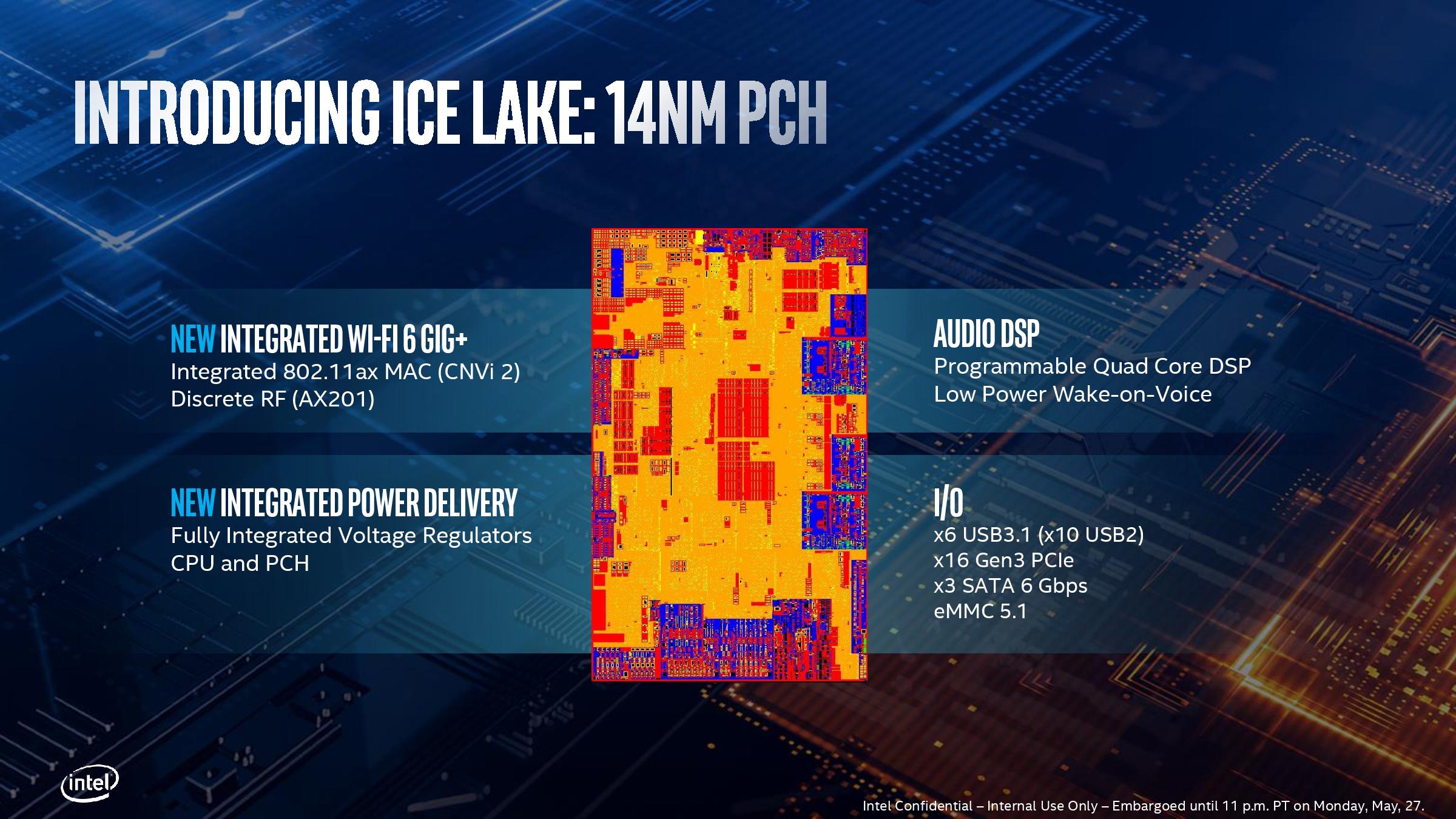
重新引入FIVR
CNVi 2
其实Intel在这两年已经在出货的芯片组里面都加入了CNVi方案的Wi-Fi模块,这种方案将Wi-Fi网卡的部分电路转移到了芯片组的内部,而仍在外面充当一个射频模块的Wi-Fi网卡就可以做的非常小了,比如M.2 2230或者以1216规格直接焊在主板上。PCH内部的网卡与在外面的RF模块通过一条Intel专有的CNVi链路进行连接。

Ice Lake PCH의 특별 CNVi 링크가 두 번째 버전 인 CNVi 2로 업그레이드되었습니다.
 물론 지원되는 Wi-Fi 표준은 여전히 외부 Wi-Fi 네트워크 카드에 의해 결정되므로 OEM 맞춤화에 편리합니다. 인텔의 움직임은 사람들이 Wi-Fi를 업그레이드하는 방식에 대한 장벽을 허물고 있습니다 (AX 라우터의 가격을 올리는 것입니다). , Intel은 현재 Wi-Fi 6 표준을 지원하는 두 개의 무선 네트워크 카드 인 AX200 / 201을 보유하고 있습니다.
물론 지원되는 Wi-Fi 표준은 여전히 외부 Wi-Fi 네트워크 카드에 의해 결정되므로 OEM 맞춤화에 편리합니다. 인텔의 움직임은 사람들이 Wi-Fi를 업그레이드하는 방식에 대한 장벽을 허물고 있습니다 (AX 라우터의 가격을 올리는 것입니다). , Intel은 현재 Wi-Fi 6 표준을 지원하는 두 개의 무선 네트워크 카드 인 AX200 / 201을 보유하고 있습니다.
Wi-Fi 6의 특정 개선 사항에 대해서는 이전 기사 인 Super Class (188)를 참조 할 수 있습니다. WiFi 6이 왜 그렇게 "6"일 수 있습니까? .
IO
이것은 단순히 데이터를 나열합니다.
- 6 USB 3.1 (5Gbps) / 10 USB 2.0
- 16 개의 PCI-E 3.0 (일반적으로 8 개는 2 개의 NVMe 인터페이스에 사용됨)
- 3 SATA 3.0
- eMMC 5.1
인텔은 UFS 지원을 언급하지 않았습니다.
요약
PCH의 변경은 주로 기존 기능의 향상으로 인해 크지 않습니다.
패키지, 터보 주파수 및 전력 소비
다양한 전력 소비 목표 및 다양한 패키징 방법 현재 Ice Lake-U와 Ice Lake-Y는 목표 TDP 가 다른 두 시리즈로 각각 15 ~ 28W, 7 ~ 12W 용으로 설계되었습니다. 향후 모바일 표준 압력 수준 TDP는 약 45W이며 데스크톱 수준은 현재 알려지지 않았습니다.
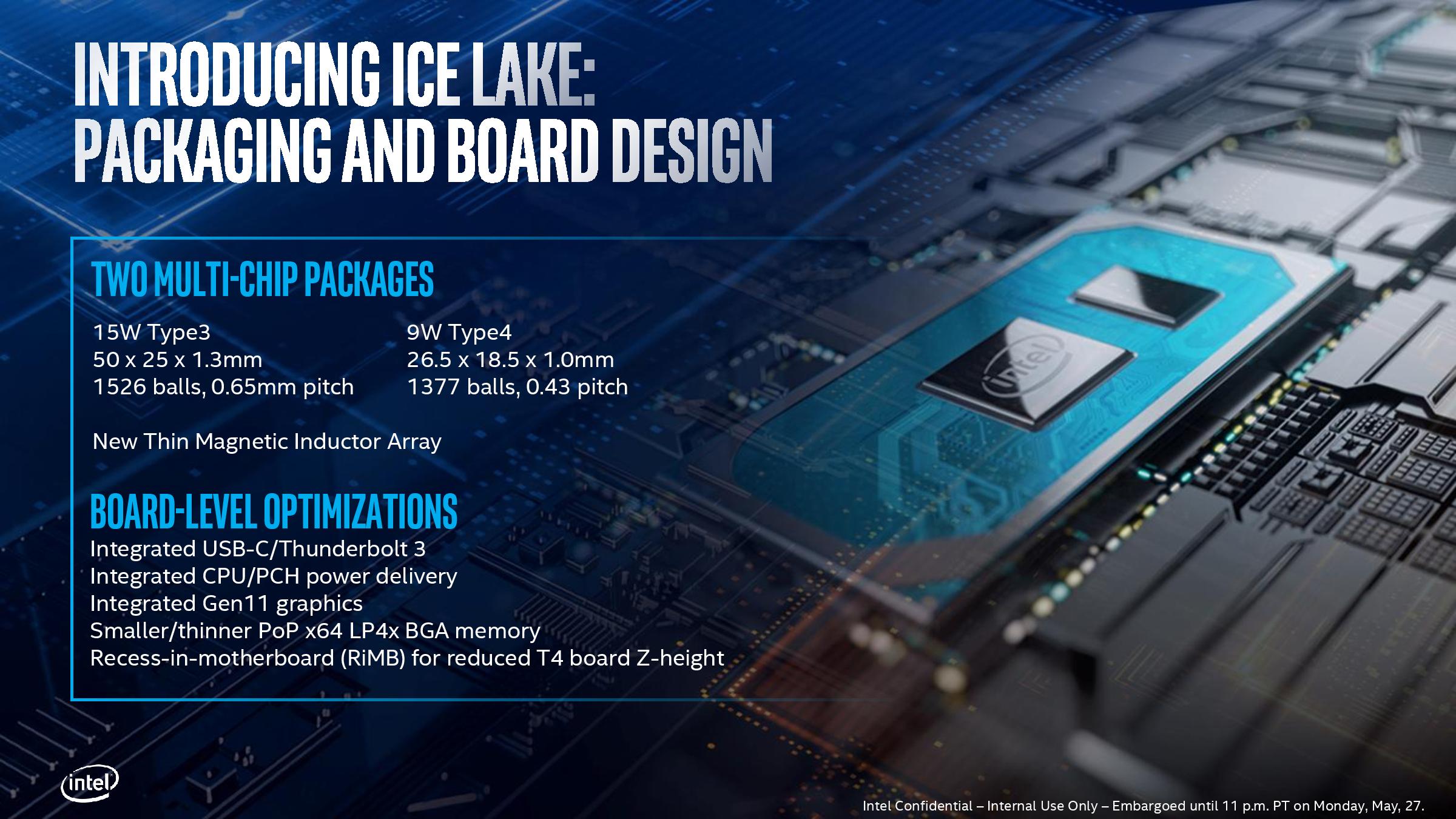 이번에 처음 출시 된 11 개의 저전압 및 초 저전압 모델도 두 가지 다른 패키지를 채택했습니다. U 시리즈는 많이 변경되지 않았으며 여전히 동일하지만 초 저전압은 평소와 다릅니다. 인텔은보다 컴팩트 한 패키징 방식을 사용합니다. 하단 접점도 비교적 단단합니다.
이번에 처음 출시 된 11 개의 저전압 및 초 저전압 모델도 두 가지 다른 패키지를 채택했습니다. U 시리즈는 많이 변경되지 않았으며 여전히 동일하지만 초 저전압은 평소와 다릅니다. 인텔은보다 컴팩트 한 패키징 방식을 사용합니다. 하단 접점도 비교적 단단합니다.

동적 조정 2.0
 새로운 다이내믹 조정 2.0 기술은 사진을보기 만하면 변경됩니다. 대략적인 의미는 Ice Lake 프로세서가 이전처럼 터보 주파수 18 초 후에 기본 주파수로 돌아 가지 않고 천천히 내려가는 것입니다. 8 초 더 길었습니다. 이 새로운 기술은 또한 기계 학습을 사용하여 CPU가 어떤 유형의 부하를 사용할지 예측 한 다음 전력 예산을 지능적으로 조정하여 터보 주파수 시간을 최대한 연장합니다.
새로운 다이내믹 조정 2.0 기술은 사진을보기 만하면 변경됩니다. 대략적인 의미는 Ice Lake 프로세서가 이전처럼 터보 주파수 18 초 후에 기본 주파수로 돌아 가지 않고 천천히 내려가는 것입니다. 8 초 더 길었습니다. 이 새로운 기술은 또한 기계 학습을 사용하여 CPU가 어떤 유형의 부하를 사용할지 예측 한 다음 전력 예산을 지능적으로 조정하여 터보 주파수 시간을 최대한 연장합니다.
요약하자면
일반적으로 Ice Lake는 핵심 구성 요소이든 다양한 외부 구성 요소이든 매우 변경된 아키텍처입니다. 사람들은 인텔이 치약을 짜낸다고하지만, 경쟁 업체의 압력 부족도 인텔이 치약을 짜는 이유라고 말할 수 있지만, 더 많은 이유는 아마도 인텔이 최근 몇 년 동안 그 과정에서 겪은 어려움 때문일 것입니다. Intel의 Tick-Tock 전략에서 Cannon Lake는 Skylake 공정의 업그레이드 버전으로 등장했지만 10nm의 어려운 생산으로 인해 Tick-Tock 전략은 완전히 실패하고 PAO-process-architecture-optimization 전략이되었습니다. 1 세대 10nm의 역할이 시작되었습니다. 그 결과 10nm는 PAO 전략 계획보다 늦었습니다. 그러나 라이벌 Zen 및 Zen + 아키텍처가 Intel에 압력을 가하기 시작했습니다. 방법이 없습니다. Skylake는 2 개의 코어를 추가하고 14nm ++를 사용하여 그 위에 있습니다. 이 정상은 거의 2 년 후 Cannon Lake도 완전히 버려졌으며 위의 최적화 중 많은 부분이 Ice Lake에 상속되었습니다.
전체 아키텍처의 관점에서 Ice Lake는 계속해서 단일 스레드 성능을 높이고 있으며 테스트 결과에서도이를 확인했습니다. 기본 주파수와 가속 주파수가 이전 세대보다 낮고 단일 스레드 성능이 균일해질 수 있습니다. 이미 쉽지 않습니다. 다중 코어를 사용하는 경우 Ringbus 제한은 약 10 개 코어 여야합니다. Mesh 아키텍처가 채택되지 않으면 향후 데스크탑 버전의 Intel Ice Lake 프로세서가 AMD의 Zen 2/3에 여전히 패배 할 것입니다.
확장 성 측면에서 Ice Lake는 더 성실합니다 .TB3 컨트롤러를 추가하면 USB 및 TB 장치가 다소 부족한 PCI-E 3.0 버스를 점유 할 필요가 없으며 향후 USB4와의 호환성도 유지됩니다. Ice Lake의 최적화되거나 업그레이드 된 버전에서 공식 USB 4 지원이 표시 될 것으로 예상됩니다.
Ice Lake는 앞으로 얼마 동안 Intel의 주요 아키텍처가 될 것이지만 데스크톱 수준에 도달하려면 시간이 걸릴 것입니다. 인텔의 현재 제품 라인도 매우 혼란 스럽기 때문에 한 가지 기사를 살펴 보겠습니다.
컴퓨터/노트북/인터넷
IT 컴퓨터 기기를 좋아하는 사람들의 모임방
| 번호 | 분류 | 제목 | 조회 수 | 날짜 |
|---|---|---|---|---|
| 공지 | 뉴스 |
구글 최신 뉴스
|
1384 | 2024.12.12 |
| HOT글 | 일반 | 아 진짜 요새 SKT 해킹 뭐시기 때문에 신경 쓰여 죽겠어 ㅠㅠ 2 | 237 | 2025.05.20 |
| 공지 | 사랑LOVE 포인트 만렙! 도전 | 4651 | 2025.03.19 | |
| 공지 | 🚨(뉴비필독) 전체공지 & 포인트안내 2 | 25847 | 2024.11.04 | |
| 공지 | URL만 붙여넣으면 끝! 임베드 기능 | 20431 | 2025.01.21 | |
| 10640 | 일반 | Synology의 4 베이 NAS 장비 "DiskStation DS416j" | 1456 | 2016.02.08 |
| 10639 | 일반 | 태블릿 PC의 충전을하면서 주변 기기를 사용할 수있는 OTG 지원 USB 허브 | 1434 | 2016.02.08 |
| 10638 | 일반 | 카페베네 상장 난항에 투자자 눈물 | 776 | 2016.02.15 |
| 10637 | 일반 | 주식, 욕심은 화를 부르고. 그 화는 고스란히 가족들에게 짜증을 부릴겁니다 | 789 | 2016.02.22 |
| 10636 | 일반 | 원익IPS 추천합니다 | 676 | 2016.02.22 |
| 10635 | 일반 | 장이 너무 안좋네요 ㅜㅜ | 707 | 2016.02.22 |
| 10634 | 일반 | 주식투자와 관련된 주식명언 | 999 | 2016.02.22 |
| 10633 | 일반 | i5-6600 i5-6500 비교 1 | 1434 | 2016.02.22 |
| 10632 | 일반 | ssd좀봐주세요 2 | 906 | 2016.02.27 |
| 10631 | 일반 | 크라운제과 어떻게 보시나요? | 458 | 2016.02.28 |
| 10630 | 일반 | 흑자예상하며 기다린보람이 있군 | 471 | 2016.02.28 |
| 10629 | 일반 | 세계 주식 주요 지수 보는곳 입니다.모르시는분들을 위해 | 646 | 2016.02.28 |
| 10628 | 일반 | 한 2월 말쯤 총선테마가 시작될걸로 예상합니다. | 562 | 2016.02.28 |
| 10627 | 일반 | 대중관계 악화로 중국에서 돈버는 기업들 급락이네요 | 684 | 2016.02.28 |
| 10626 | 일반 | 주식 생초보인데 알려주실수 있으신가요? | 515 | 2016.02.28 |
| 10625 | 일반 | 11시정도만 잘 넘기면 될거같은데.. | 478 | 2016.02.28 |
| 10624 | 일반 | 요즘 한종목에 꽂혀서 분할매수하는데요. | 565 | 2016.02.28 |
| 10623 | 일반 | 본인 명의로 핸드폰 두개 개설 하면 문제 생기나요? 1 | 1154 | 2016.03.01 |
| 10622 | 일반 | 단말기대금 일시불납 가능한가요? 1 | 781 | 2016.03.05 |
| 10621 | 일반 | 노트4 배터리 공유?? 1 | 1749 | 2016.03.05 |
| 10620 | 일반 | 금호타이어 어떻게 보시나요? | 650 | 2016.03.05 |
| 10619 | 일반 | 해외에서 사용하던 도메인을 구입했는데 헉.. | 568 | 2016.03.09 |
| 10618 | 일반 | 축구 페널티킥 선방 탑10 | 469 | 2016.03.12 |
| 10617 | 일반 | SSD의 성능을 유지하기위한 유지 관리 기술 | 1068 | 2016.03.15 |
| 10616 | 일반 | 저렴한 Skylake 버전 Xeon 마더보드 'GA-X150M-PRO ECC」 | 874 | 2016.03.15 |
| 10615 | 일반 | G5 vs S7 1 | 626 | 2016.03.18 |
| 10614 | 일반 | 스테레오믹스 소리가 안납니다 1 | 1104 | 2016.03.19 |
| 10613 | 일반 | 스피커를 항상 켜 놓는데요. 노이즈??? 소리가 납니다. 1 | 850 | 2016.03.19 |
| 10612 | 일반 | M2 메모리 추천 1 | 911 | 2016.03.19 |
| 10611 | 일반 | 모니터 단자 HDMI, DP & 오디오 관련 문의 1 | 865 | 2016.03.19 |