컴퓨터/노트북/인터넷
IT 컴퓨터 기기를 좋아하는 사람들의 모임방
단축키
Prev이전 문서
Next다음 문서
단축키
Prev이전 문서
Next다음 문서
캐시 운영 전략
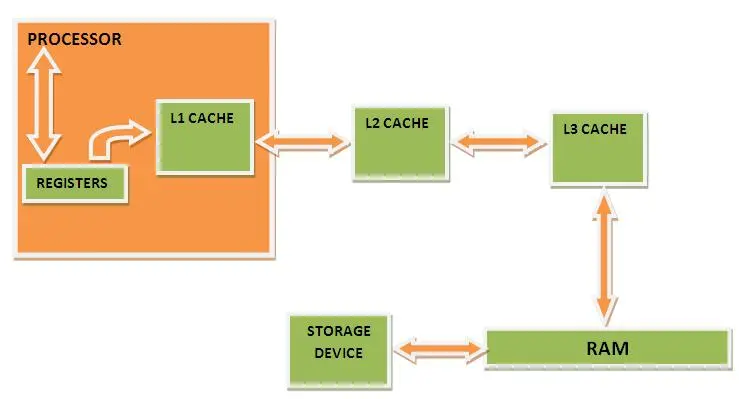
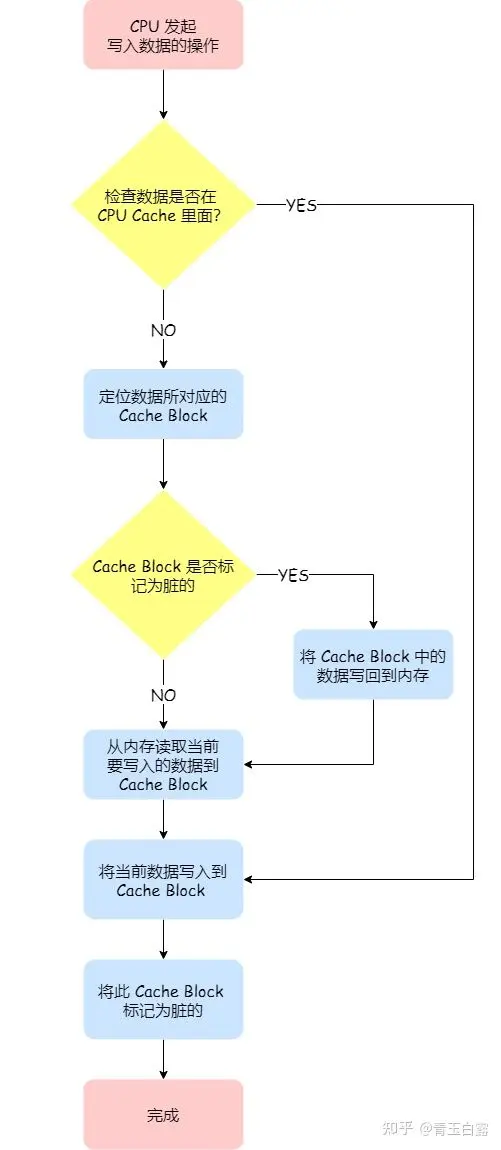
CPU 읽기 및 쓰기 프로세스의 개략도
이미지 출처: " 캐시 메모리 작동 방식" https://www.engineersgarage.com/how -cache-memory-works/
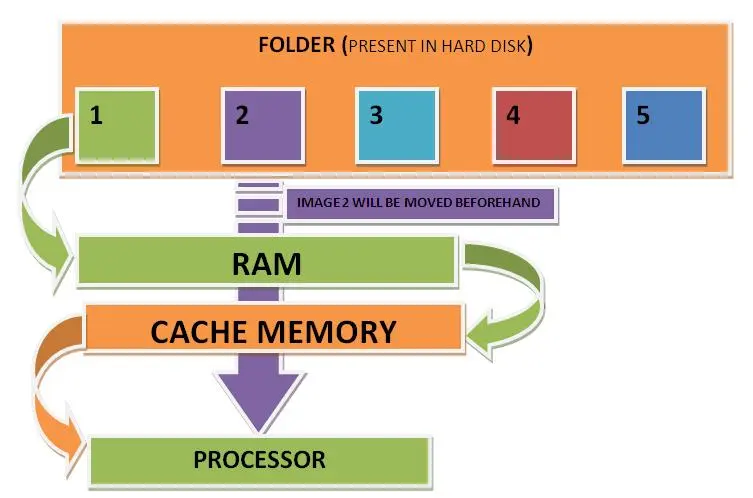
내부 구조는 어떤가요? 어떻게 작동하나요? CPU는 특정 메모리 주소의 데이터가 캐시에 있는지 어떻게 확인합니까? 즉, 메모리 주소를 기준으로 캐시 적중은 어떻게 이루어 집니까?

캐시 작동 방식
캐시의 물리적 구조는 S, E, B의 세 가지 매개변수로 설명할 수 있습니다.
S: Set의 개수를 나타냅니다. Set이란 무엇인가요? 캐시가 여러 그룹으로 나누어지고 각 그룹에 여러 캐시 라인이 있음을 나타냅니다.
E: 캐시 라인 수를 나타내며, 각 세트에 캐시 라인이 몇 개 있는지 나타냅니다.
B: 캐시 라인에 저장할 수 있는 바이트 수를 나타내며, 앞에서 언급한 64바이트와 같이 캐시 라인에 로드할 수 있는 바이트 수를 나타냅니다.
왜 집합을 나누어야 합니까? Cache Line을 직접하는 것이 낫지 않나요? 답변: 아니요, Cache Line을 찾는 과정은 1:1 비교가 필요합니다. 하위 테이블 방법인 Set을 사용하면 검색 속도가 빨라질 수 있습니다. 믿을 수 없다면 다음 주소 지정 방법을 살펴보세요.
그렇다면 메모리 주소를 통해 캐시에 있는지 확인하는 방법은 무엇입니까? 메모리 주소는 다음과 같이 나눌 수 있습니다.
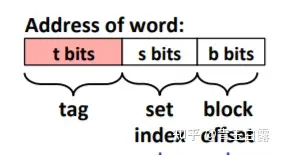
메모리 주소를 얻고 그것이 캐시에 있는지 확인하려면 다음을 수행하십시오.
첫 번째 단계는 중간의 비트를 꺼내서 해시하여 해당 비트가 어느 세트에 있는지 확인하는 것입니다.
해싱에서 중간 숫자를 사용하는 이유는 개인적으로 지역성의 원리를 고려한 것이라고 생각하는데, 데이터의 높은 숫자를 사용하면 프로그램에서 동일할 확률이 프로그램에서 동일할 확률이 훨씬 더 높습니다. 중간 숫자를 취합니다(숫자가 높을수록 공간이 커지고 공간이 커집니다. 해시 충돌이 발생하기 쉽습니다). 따라서 중간 항목을 선택하면 지역성 원칙을 고려할 수 있을 뿐만 아니라 대규모 해시 충돌도 피할 수 있습니다.
두 번째 단계에서는 상위 t-bit 데이터를 꺼내서 Set에 있는 각 Cache Line의 태그와 비교하여 동일한지 확인하고, 동일한 경우 v(valid) 플래그가 1인지 확인합니다. 1이면 캐시 히트(cache hit)를 뜻하고, 찾지 못하거나 v가 0이면 캐시 미스(cache miss)를 뜻하며, 그러면 캐시는 메모리에 있는 해당 데이터만 읽을 수 있게 된다. . 간단히 말하면, 태그는 더 높은 숫자와 비교되는 데이터입니다.
세 번째 단계는 두 번째 단계가 완료되면 하위 b비트 데이터를 꺼내고, 이 데이터를 기준으로 가져올 워드 데이터의 위치를 결정한 후 데이터를 읽는다.
캐시 단위는 바이트입니다.
캐싱 전략
또한 Set과 Cache Line의 정량적 관계에 따라 캐시는 크게 세 가지 유형으로 나눌 수 있습니다 .
- 직접 매핑 캐시: 여러 세트, 각 세트에는 캐시 라인이 하나만 있습니다.
- E-way 그룹 연결 캐시: 여러 세트, 각 세트에는 E 캐시 라인이 있습니다.
- 완전 연결 캐시(Fully Connected Cache): Set은 하나이지만 그 안에 Cache Line이 여러 개 있어 모든 Cache Line을 순회해야 하므로 매우 비효율적입니다.
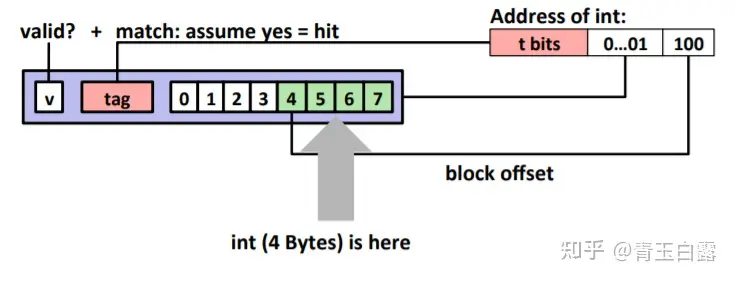
직접 지도 캐시
양방향 그룹 연결 캐시
글쓰기 전략
연속 쓰기与다시 쓰기
이전에 캐시가 데이터에 대한 CPU 액세스 속도를 높일 수 있다고 언급했습니다. 따라서 다음과 같은 질문이 있습니다. CPU가 캐시의 데이터를 수정하는 경우 해당 데이터를 언제 어떻게 메모리에 다시 써야 합니까? 즉, 캐시와 메모리 사이의 데이터 동기화 문제를 어떻게 처리할 것인가입니다.
캐시에 쓰는 방법에는 두 가지가 있습니다.
Write Back: CPU가 캐시에 쓸 때 캐시의 콘텐츠만 수정하고 더티로 표시하며, 제거되면 DDR을 다시 씁니다.
연속 쓰기(직접 쓰기/전체 쓰기): CPU 쓰기 적중 시 데이터는 캐시 및 DDR에 기록되어야 하며 일반적으로 쓰기 버퍼가 사용됩니다.
쓰기 할당(Write Allocation): CPU가 실수를 기록하면 먼저 DDR에 있는 데이터를 캐시로 전송하고 캐시에서 수정한 후 다시 쓰기를 사용합니다.
비쓰기 할당(비쓰기 할당): CPU가 쓰기를 놓친 경우 DDR만 쓰고 연속 쓰기와 결합됩니다.

쓰다
캐시의 수정된 데이터와 메모리의 원본 데이터의 일관성을 어떻게 보장합니까?
직관적으로 가장 간단한 방법은 데이터를 수정할 때 캐시와 메모리에 동시에 데이터를 쓰는 것입니다.
간단히 말하면 캐시에 있는 데이터가 먼저 업데이트된 다음(데이터가 캐시에 있는 경우) 데이터가 메모리에 기록됩니다.
이 방법은 가장 직관적이고 간단하지만 성능 소모가 가장 큽니다. 데이터가 수정될 때마다 데이터를 메모리에 써야 하기 때문에 캐시 성능을 최대한 발휘할 수 없고 이득이 손실보다 크기 때문입니다.

다른 CPU에 의해 로드될 때 캐시가 업데이트되는 것으로 표시하는 방법은 무엇입니까? 각 캐시 라인은 로드된 이후 업데이트가 발생했는지 식별하기 위한 더티 비트를 제공합니다. (CPU가 로딩될 때 앞서 언급한 것처럼 바이트 단위가 아닌 조각 단위로 로드됩니다.)

1. CPU는 Cache에 데이터를 쓸 때 메인 메모리에도 데이터를 쓰며, 데이터는 항상 일관되게 저장됩니다.
2. CPU가 주 메모리에 데이터를 쓰는 속도가 매우 느리기 때문에 쓰기 버퍼 큐가 필요합니다.
3. Cache1 및 Cache3에 데이터를 쓸 때 특정 방식으로 복사본이 쓰기 버퍼에 기록되고 CPU는 계속해서 다른 작업을 수행할 수 있습니다. 쓰기 버퍼의 데이터는 특수한 방식으로 메인 메모리에 기록됩니다. 하드웨어 회로.
4. 쓰기 작업이 빈번하게 발생하면 쓰기 버퍼가 가득 차게 되는데, 이때 쓰기 버퍼 포화로 인해 CPU가 차단됩니다.
다시 쓰기
연속 쓰기 작업은 캐시가 가져야 하는 성능을 최대한 발휘할 수 없습니다. 그렇다면 이를 최적화하는 방법은 무엇입니까?
가능할까요... 매번 캐시의 데이터만 업데이트하고, 캐시를 메모리에 다시 써야 하는 경우에만 캐시를 메모리에 씁니다.
이 방법은 이전 방법보다 확실히 더 효율적일 것으로 예상할 수 있습니다. 그렇다면 캐시는 메모리에 무엇을 다시 써야 할까요? ——이때 캐시가 교체됩니다.
Cache의 용량이 너무 작아(KB 단위로 측정), 읽은 Cache 데이터가 항상 공간을 차지할 수 없으며, 이는 메모리 페이지 교체와 유사한 Cache Line 교체도 포함하며, 일반적으로 사용되는 알고리즘에는 LRU, LFU가 있습니다.
즉, 캐시 라인이 교체되지 않은 경우 업데이트된 데이터를 메모리에 다시 쓸 필요가 없으며 캐시에 있는 데이터만 업데이트하면 됩니다.캐시 라인이 새로운 캐시 데이터로 교체되는 경우에만 , 우리는 데이터가 메모리에 다시 기록됩니다.

먼저 Cache에 있는 데이터를 수정한 후 더티 비트를 사용하여 수정 여부를 확인하고, 수정된 경우 주 메모리에 기록되며, 수정되지 않은 경우에는 쓸 필요가 없습니다. 다시 CPU------>캐시------>메인 메모리로 돌아갑니다.
이미지 출처(고급 기사) : https://zhuanlan.zhihu.com/p/14 4537640
CPU 캐시(캐시)에 대한 간략한 분석 https://zhuanlan.zhihu.com/p/34 0573903
쓰기 할당
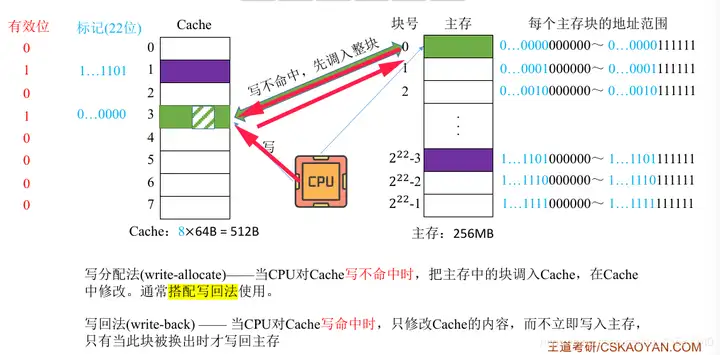
누락된 부분이 있으면 먼저 주 메모리의 데이터를 Cache로 전송한 다음 Cache에 쓰고 마지막으로 Write-back 방식을 사용하여 Cache에 있는 데이터를 주 메모리로 반환합니다.
쓰기 금지 할당
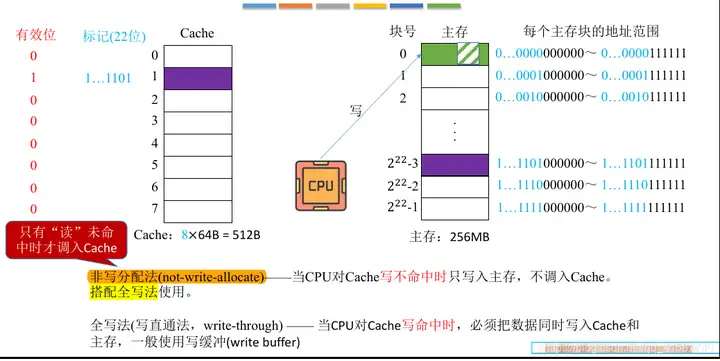
CPU는 캐시와 상호작용하지 않고 메인 메모리에 직접 씁니다.
가설 1: 전체 쓰기 방식과 쓰기별 할당 방식이 결합된다. (1) 첫 번째 캐시 쓰기 실패 후 주 메모리를 업데이트하고 블록을 캐시로 전송해야 합니다. (2) 그런 다음 이 블록을 n번 기록합니다. 이때 (1)의 쓰기 할당 방법으로 인해 Cache가 업데이트되었습니다. 이때 쓰기 적중이 발생하므로 주 메모리와 Cache를 n번 기록해야 합니다. 동시에.
실제 상황 1: 전체 쓰기 방법과 비쓰기 할당 일치. (1) 첫 번째 캐시 미스가 발생하면 주 메모리가 업데이트되고 캐시가 전송되지 않습니다. (2) 다시 n번 쓰기 이때 (1) 주 메모리 블록이 Cache로 옮겨지지 않았기 때문에 여전히 Miss이므로 주 메모리에는 n번만 쓴다.
저자 : 슈퍼 바보
링크: https://www.zhihu.com/question/6256 2256/answer/1148553090
출처 : Zhihu
저작권은 저자에게 있습니다. 상업적 전재의 경우 저자에게 연락하여 허가를 받으시고, 비상업적 전재의 경우에는 출처를 밝혀주시기 바랍니다.
다중 레벨 캐시
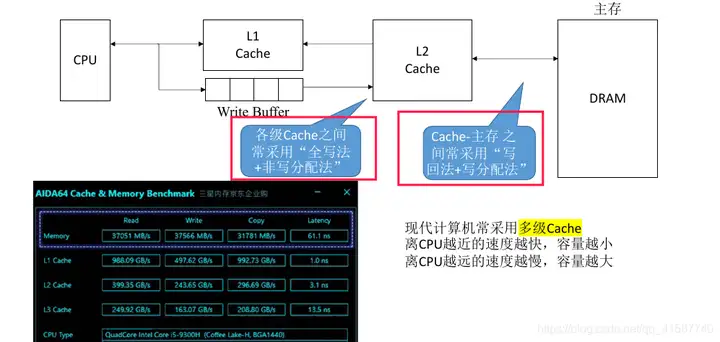
https://blog.csdn.net/qq_41587740/article/details/109104962
그림에서 현재 캐시 데이터 블록을 더티로 표시하는 것은 캐시 라인의 태그로 표시하는 것을 의미합니다. 이에 대해서는 나중에 메모리 일관성 섹션에서 자세히 설명하겠습니다.
캐시 일관성 프로토콜 MESI
후기입 메커니즘은 캐시 성능을 최대한 활용할 수 있으므로 오늘날 대부분의 캐시 메커니즘은 이 방법을 사용합니다. 그러나 이로 인해 또 다른 문제가 발생합니다. 멀티 코어 시나리오에서 캐시와 메모리의 일관성을 어떻게 보장할 수 있을까요?
CPU에 A와 B라는 두 개의 코어가 있고, L1과 L2는 서로 독립적이라고 가정하고, A와 B의 캐시에서 변수 i를 읽는다고 가정합니다. 이때, i=0입니다.
코어 A에서 i의 값이 1로 변경되었지만 코어 B에서 알려진 i의 값은 여전히 0이므로 알 수 없는 오류가 발생할 수 있다고 가정합니다.
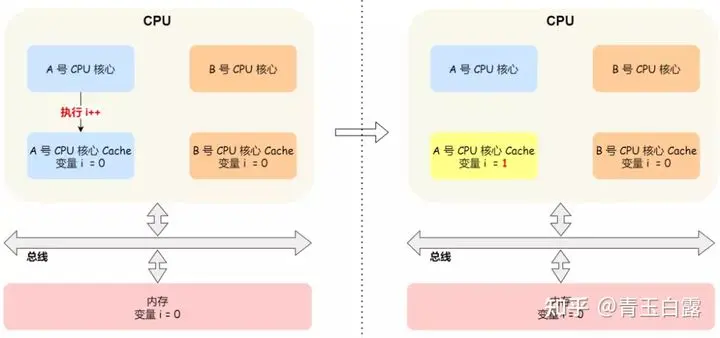
이는 멀티 코어 시나리오에서 캐시 데이터 불일치 문제입니다. 어떻게 해결하나요?
이 문제를 해결하려면 다음 두 가지 사항이 보장되어야 합니다.
CPU 코어가 데이터에 대한 업데이트 작업을 수행할 때 다른 CPU 코어와 메모리에 해당 작업에 대해 "알려야" 합니다. 이것이 소위 "쓰기 전파"입니다(이 처리 메커니즘은 여러 사람이 공동으로 작업하는 문서에도 필요합니다). '방송'이라고도 할 수 있습니다. 이를 달성하는 일반적인 방법은 버스 스누핑입니다. 코어가 데이터를 업데이트하면 버스를 통해 다른 코어로 데이터를 브로드캐스트합니다. 다른 코어는 항상 버스의 동적 특성을 모니터링합니다. 데이터 업데이트가 수신되면 , 해당 데이터가 해당되는지 확인합니다. 데이터가 자체 캐시에 존재하며, 그렇다면 업데이트하세요. 데이터가 업데이트될 때마다 버스에 브로드캐스트되므로 버스에 엄청난 부하 압력이 가해지게 됩니다.
데이터에 대한 멀티 코어 수정은 직렬화되고 트랜잭션되어야 합니다. 간단히 말해서, 코어 A가 i를 수정하고 코어 B도 데이터를 수정하면 해당 수정 사항이 다른 코어에 "전파"됩니다. 이는 필연적으로 누가 코어 AB로부터 메시지를 먼저 받는지에 대한 문제를 수반하게 됩니다.
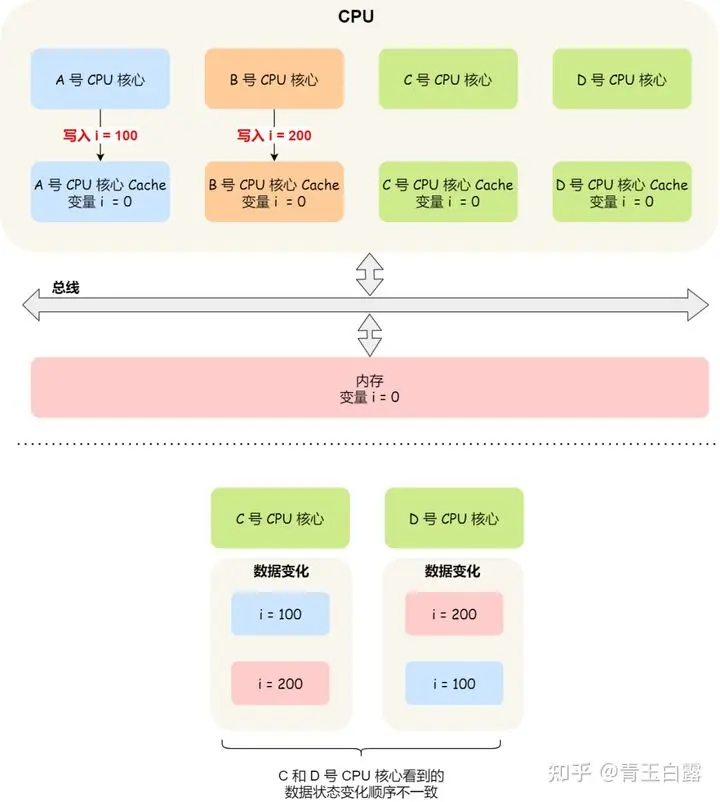
잠깐, 멀티스레드 데이터 동기화에서 유사한 데이터 동기화 문제가 발생한 적이 있습니까? 당시 우리는 문제를 해결하기 위해 잠금을 도입했으며, 마찬가지로 캐시 일관성 문제에 대한 잠금 메커니즘도 도입할 수 있습니다. 잠금을 획득한 코어만이 데이터를 수정할 수 있습니다.
위에서 언급했듯이 버스 스니핑에만 의존하면 버스 부하가 증가하고 효과가 좋지 않습니다. 실제로 캐시의 데이터를 M, E의 네 가지 상태로 표시하는 MESI 프로토콜이 널리 사용됩니다. , S, I. 캐시 일관성은 이 네 가지 상태 간의 관계를 통해 달성됩니다.
M, 수정됨은 데이터, 즉 위에서 언급한 "더티" 데이터가 수정되었으며 적절한 시점에 메모리에 다시 기록되어야 함을 나타냅니다.
E, Exclusive는 데이터가 배타적이라는 뜻으로 현재 특정 코어에만 데이터가 존재하고 다른 코어에는 해당 데이터가 없으므로 소위 다른 코어로 브로드캐스트할 필요가 없다는 의미이며, 캐시 일관성 문제가 없습니다.
S, Shared는 데이터 독점 상태에서 전송되는 데이터 공유를 나타냅니다. 이는 데이터가 여러 코어에 존재하며 현재 캐시 일관성 문제가 있음을 의미합니다.
I, Invalidated는 데이터가 만료되었으며 캐시 블록 데이터가 폐기될 수 있음을 나타냅니다. (높은 동시성 조건에서 두 CPU는 동시에 변수 a를 수정하고 변경 사항을 버스에 보내 해당 캐시 라인을 M으로 변경할 수 있습니다. 이 버스는 해당 중재 메커니즘을 사용하여 중재하고 그 중 하나를 M 상태로 설정하고 다른 하나를 I 상태로 설정하며 I 상태의 캐시 라인 수정은 유효하지 않습니다.
MESI의 4가지 상태 플래그는 캐시 라인에 저장됩니다.
몇몇 친구들은 이미 막연하게 느꼈을 거라 믿습니다. 이것은 유한 상태 기계입니다:
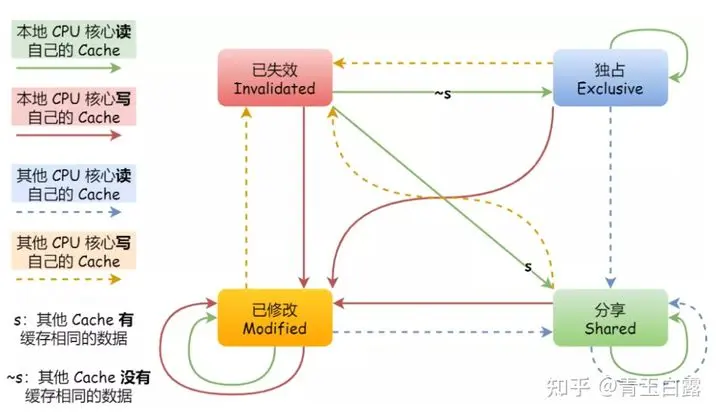
유한 상태 기계(Finite State Machine)만으로는 이해하기 어려울 수 있지만, 다음 예시를 통해 MESI 프로토콜이 어떻게 작동하는지 단계별로 분석해 보겠습니다. 링크를 참고 하세요 :
먼저, CPU 1 코어는 메모리의 변수 i를 자체 캐시에 로드하고 캐시에서 상태를 E(독점)로 표시합니다.
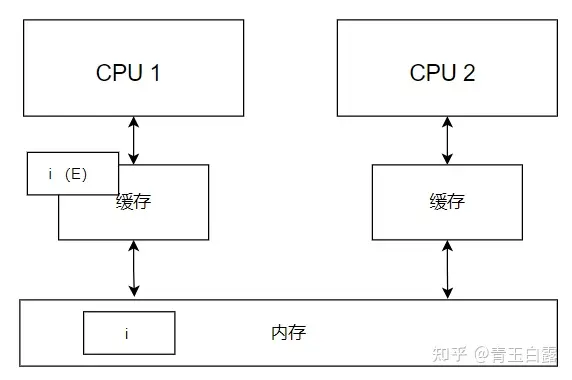
참고: L1, L2, L3 캐시는 단순화를 위해 그려지지 않았으며 그림의 캐시는 L12를 나타내고 L3은 메모리에 통합되어 있다고 볼 수 있습니다.
이후 CPU 2는 변수 i를 읽는데, 이때 CPU1은 버스 스니핑을 통해 CPU2의 동작을 학습하고 자신의 캐시 I의 상태를 S(공유)로 표시하고, CPU2의 캐시도 S로 표시합니다.

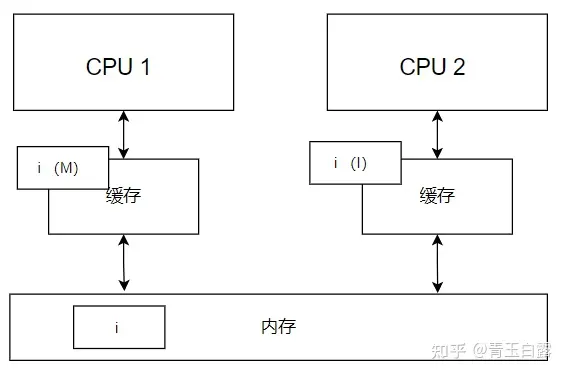
그런 다음 CPU 1은 변수 i를 수정하고 캐시의 상태를 M(수정됨)으로 변경했습니다. CPU 2는 버스 스니핑을 통해 자신의 데이터 i를 I(잘못됨)로 표시했습니다.
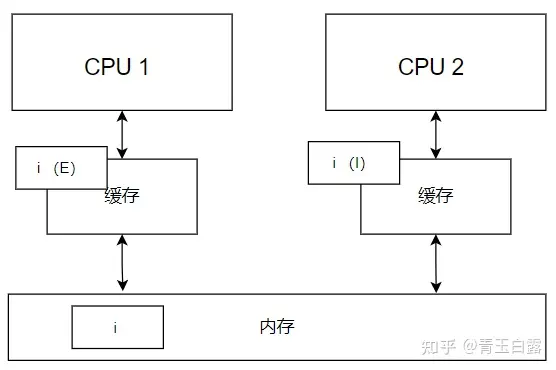
그 후, CPU1은 변수 i를 메모리에 다시 쓰고 그 상태를 E(exclusive)로 표시합니다. CPU2의 변수 a가 I(유효하지 않음) 상태로 설정된 후에는 변수 a의 수정만 보장합니다. 그러나 CPU2는 CPU1이 변수 a를 E(배타적) 상태로 설정하기 전에 메모리에서 변수 a를 다시 읽을 수 있습니다. 이는 어셈블리 명령에서 메모리를 다시 로드하기 위해 CPU2가 필요한지 여부에 따라 다릅니다.
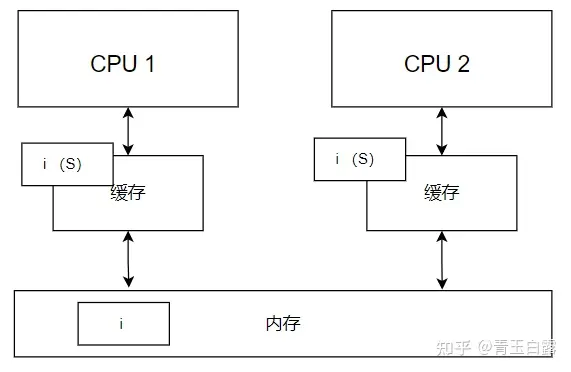
마지막으로, 어떤 순간에 CPU2는 변수 i에 접근해야 하지만 만료된 것을 발견하여 다시 메모리에서 변수 i를 읽어야 합니다. 이때 상태는 다음과 같습니다.
위 내용은 MESI 프로토콜의 작업 프로세스에 대한 간단한 설명일 뿐이며 실제 작업 프로세스는 매우 복잡하며 세 가지 중요한 사항이 있습니다.
프로세서가 배타적 모드를 사용하여 캐시 라인 로드를 요청하면 다른 프로세서는 캐시 라인의 모든 복사본을 무효화합니다. 해당 캐시 라인의 로컬 캐시 라인을 수정한 프로세서는 먼저 이를 메모리에 다시 써야 하며, 그런 다음 첫 번째 프로세서의 로드 요청이 충족될 수 있습니다.
프로세서가 공유 모드를 사용하여 캐시 라인을 로드하도록 요청할 때 배타적 모드에서 라인을 로드하는 모든 프로세서는 상태를 공유로 설정해야 하며 해당 로컬 해당 캐시 라인을 수정한 모든 프로세서는 다음을 수행해야 합니다. 라인은 주 메모리에 다시 기록되어야 합니다. 첫 번째 프로세서의 로드 요청이 충족될 수 있습니다.
캐시가 가득 차면 캐시 라인을 교체해야 할 수도 있습니다. 회선이 공유되거나 배타적이면 간단히 삭제할 수 있습니다. 그러나 라인이 수정된 경우 먼저 메모리에 다시 쓴 다음 삭제해야 합니다.
MESI의 상태 비트 수정은 버스 스니핑 메커니즘을 기반으로 하며 전체 프로세스는 하드웨어 수준에서 구현됩니다.
교체 전략
Cache의 작동 원리는 최신 데이터를 저장하려고 시도하는데, 새로운 블록이 주 메모리에서 Cache로 전송되고 Cache의 사용 가능한 공간이 가득 차면 Cache 교체 문제가 발생합니다.
대체 문제는 캐시 구성과 밀접하게 관련되어 있습니다. 직접 매핑된 캐시의 경우 이 사용 가능한 위치에서 주 메모리 블록만 교체하면 됩니다. 완전 연관 및 집합 연관 캐시의 경우 교체가 필요합니다. 사용 가능한 여러 위치에서 주 메모리 블록 위치를 선택하고 캐시에서 주 메모리 블록을 교체합니다.
일반적으로 사용되는 대체 알고리즘에는 세 가지가 있습니다.
1. 가장 적게 사용되는(LFU) 알고리즘
LFU(Least 빈번하게 사용됨) 알고리즘은 일정 기간 동안 가장 적게 액세스된 블록을 교체합니다. 각 블록마다 카운터가 설정되어 0부터 계산되기 시작합니다. 액세스할 때마다 액세스된 블록의 카운터가 1씩 증가합니다. 교체가 필요한 경우 카운트 값이 가장 작은 블록이 교체되고 모든 블록의 카운터가 지워집니다.
이 알고리즘은 계산 주기를 특정 블록을 두 번 교체하는 간격으로 제한하므로 최근 액세스 상황을 엄격하게 반영할 수 없으며 새로 전송된 블록을 쉽게 교체할 수 있습니다.
2. 가장 최근에 사용된(LRU) 알고리즘
LRU(Least Recent Used) 알고리즘은 CPU의 가장 최근에 사용된 블록을 대체합니다. 이 대체 방법을 사용하려면 어느 블록이 가장 최근에 사용된 블록인지 확인하기 위해 언제든지 캐시에 있는 각 블록의 사용량을 기록해야 합니다. 블록마다 카운터도 설정되어 있으며 캐시가 히트할 때마다 히트 블록 카운터가 지워지고 다른 블록의 카운터가 1씩 증가합니다. 교체가 필요한 경우 카운트 값이 가장 큰 블록이 교체됩니다.
LRU 알고리즘은 상대적으로 합리적이지만 구현이 복잡하고 시스템 오버헤드가 큽니다. 이 알고리즘은 방금 Cache로 전송된 새로운 데이터 블록을 보호하며 적중률이 높습니다.
3. 무작위 교체
가장 간단한 교체 알고리즘은 무작위 교체입니다. 무작위 교체 알고리즘은 캐시 상황을 완전히 무시하고 단순히 무작위 숫자를 기반으로 교체할 블록을 선택합니다. 무작위 교체 알고리즘은 하드웨어에서 구현하기 쉽고 처음 두 알고리즘보다 빠릅니다. 단점은 적중률과 Cache 효율성이 떨어진다는 점입니다.
캐시 적중률은 교체 알고리즘과 관련된 것 외에도 캐시 용량 및 블록 크기와도
관련이 .
다시 쓰기 알고리즘
캐시의 내용은 주 메모리 내용의 하위 집합일 뿐이므로 주 메모리 내용과 일치해야 하며, CPU가 캐시에 쓰면 캐시의 내용이 변경됩니다. 이를 위해 쓰기 작업 전략을 사용하여 캐시 콘텐츠를 주 메모리 콘텐츠와 일관되게 유지할 수 있습니다.
다시 쓰기 방법
CPU가 캐시 적중을 쓸 때 캐시 내용을 즉시 메인 메모리에 쓰지 않고 수정만 하며, 블록이 스왑 아웃될 때만 메인 메모리에 다시 쓰여집니다.
이 방법을 사용하여 캐시에 쓰고 주 메모리에 쓰는 작업은 비동기식으로 수행되므로 주 메모리에 대한 액세스 횟수가 크게 줄어들지만 데이터 불일치의 숨겨진 위험이 있습니다. 이 방법을 구현할 때 각 캐시 블록은 수정 비트로 구성되어 이 블록이 CPU에 의해 수정되었는지 여부를 반영해야 합니다.
전체 작성 방법
쓰기 캐시에 도달하면 캐시와 주 메모리에서 동시에 쓰기 수정이 발생합니다.
이 방법을 사용하면 캐시 쓰기와 메인 메모리 쓰기가 동시에 수행되므로 캐시와 메인 메모리 간의 콘텐츠 일관성이 더 잘 유지됩니다. 이 방법을 구현할 때 Cache의 각 블록은 수정 비트 및 해당 판단 로직을 설정할 필요가 없지만, Cache에는 CPU가 메인 메모리에 쓰기 작업을 수행하는 캐시 기능이 없으므로 Cache의 효율성이 떨어집니다. .
한 번만 작성하는 방법
Write-Once 방식은 Write-back 방식을 기반으로 Full-Write 방식을 결합한 쓰기 동작 전략으로, Write Hit 및 Write Miss 처리 방법은 기본적으로 Write-back 방식과 동일하지만 첫 번째 쓰기 적중은 유지 관리를 용이하게 하기 위해 동시에 주 메모리에 기록되어야 합니다. 시스템에 있는 모든 캐시의 일관성.
멀티코어/멀티스레드 환경에서의 캐시 교체 전략
캐시 교체에 관해서는 처음에는 pseudo-random, LRU(true/psuedo)만 알고 있었는데, 나중에 RRIP에 대해 알게 되었고, 최근 smt/cmp 하에 타겟 교체 알고리즘 최적화가 있는지 살펴보던 중 일부를 기록해 봤습니다. 내가 본 것들:
산업:
파워7: SMT4 | 32kB L1 | PLRU
파워8:SMT8 | 32kB L1 | PLRU+트루 LRU
종이:
공정한 캐시 공유 (처음에 이 문서를 읽었습니다. 주로 몇 가지 공정성 판단 지표를 권장합니다. 알고리즘 측면에서는 비교적 간단하게 느껴지지만 매개변수 조정 측면에서는 더 자세히 설명되어 있습니다.)
• 각 스레드의 누락률을 기록한 다음 교체 스레드 우선순위를 동적으로 조정합니다.
• 실제로 각 스레드 할당의 최대값을 동적으로 조정하여 실패율이 너무 높을 경우 이 스레드의 최대 할당값을 늘려서 최대한 교체되지 않도록 하십시오.
바이모달 삽입 정책(BIP)
• LRU 알고리즘과 비교하여 라인의 일부는 LRU 위치에 배치되고 다른 작은 부분은 MRU 위치에 배치됩니다(교체 알고리즘을 통해 라인의 일부를 쉽게 교체할 수 있도록 하는 것과 동일하며 다음과 유사한 기능을 수행함). 예약하다)
세트 결투 모니터링(SDM)
• 서로 다른 대체 알고리즘을 사용하여 특정 두 세트의 실패율을 계산하고 이를 사용하여 다른 모든 세트에 대한 대체 알고리즘을 결정합니다(대체 알고리즘의 선택은 여전히 매우 거시적인 문제이며 특정 세트에 국한되지 않음을 알 수 있습니다). 특정 세트)
동적 삽입 정책(DIP)
• 여기서는 SDM을 사용하여 BIP와 LRU 중에서 선택합니다.
스레드 적응형 동적 삽입 정책(TADIP)
• DIP와 비교하여 스레드별 모니터링 및 제어 기능이 추가되었습니다.
최근에 사용되지 않음(NRU)
• 각 CL은 1비트를 사용하여 이력 정보를 기록하고, 히트는 해당 비트를 클리어하고, 미스는 모든 비트를 설정하며, 백필 시 항상 way0부터 시작합니다(어느 정도 정적 우선순위). PLRU와는 또 다른 유형의 LRU라고 볼 수 있습니다. -친숙한 구현; (NRU는 RRIP의 프런트엔드 구현입니다. PLRU인 경우 직관적으로 RRIP로 확장할 수 없습니다.)
재참조 간격 예측(RRIP)
• NRU 카운터를 최적화하고 단일 비트를 여러 비트로 확장하여 더 많은 기록 정보를 기록할 수 있습니다.
• 구체적으로 SRRIP와 DRRIP로 구분되며 후자는 DIP와 유사하며 SRRIP를 기반으로 BRRIP가 추가되고(역 SRRIP로 이해될 수 있음) SDM이 최종 교체 알고리즘을 선택합니다.
• 멀티스레드의 경우 TADRRIP을 TADIP처럼 만들 수 있습니다.
요약하다
지금까지 이 문서에서는 여러 스레드가 서로 다른 작업 부하를 실행할 때 최적의 성능을 달성하는 방법에 대해 논의했습니다.
1. 기본적으로 L1 캐시에서 대체 알고리즘 최적화를 본 적이 없으며 L2 또는 LLC에서는 더 많습니다. 전력 시리즈의 구현도 이를 확인합니다. 캐시 크기가 작업 부하에 비해 너무 작으면 기본 LRU 알고리즘은 그것;
2. 일반적으로 동적 조정 또는 소프트웨어 사전 프로파일링과 정적 구성이라는 두 가지 옵션이 있습니다.
3. 일반적으로 모니터와 곡의 크기는 매우 거시적이며 특정 세트만을 대상으로 하는 것이 아닙니다.
4. 서로 다른 스레드가 리소스(예: 잠금 등)를 놓고 경쟁하는 상황에 대해서는 논의하지 않겠습니다. 논의할 공통 작업량이 없는지, 아니면 너무 궁지에 몰린 상황이라 논의가 별 의미가 없는 것인지 궁금합니다. (소프트웨어 수준에서 이 문제를 논의하는 것으로 보이는 잠금 관련 기사를 여러 개 찾았습니다.)
링크 : https://www.jianshu.com/p/357153e15adb _
협회 (연관성)
캐시 교체 전략은 메인 메모리의 데이터 블록이 캐시의 어디에 복사될 것인지 결정하는데, 데이터 조각에 해당하는 캐시 라인이 하나만 있는 경우(캐시 라인 1개 크기) 이를 "직접 매핑" 맵이라고 합니다. "; 데이터 블록이 캐시의 임의의 캐시 라인에 대응할 수 있는 경우 이를 "Full-Associative"라고 합니다. 현재 더 많은 구현 방법은 "N Way Group Connection(N Way)" Set-Associative)" 방법을 사용하는 것입니다. 즉, 메모리의 특정 데이터 조각이 캐시의 N 위치에 나타날 수 있으며 N은 2, 4, 8, 12 또는 기타 값일 수 있습니다.
직접 매핑

이는 다대일 매핑 관계입니다. 이 매핑 방법에서는 주 메모리의 각 데이터 블록에 해당하는 캐시 라인이 하나만 있을 수 있으므로 직접 매핑을 "단일 방향 집합 연관"이라고도 합니다. 1990년대 초반에는 다이렉트 매핑이 당시 가장 유행했던 메커니즘이었으며, Alpha 21064, 21064A, 21164의 L1 D Cache와 I Cache는 모두 다이렉트 매핑을 사용했습니다. 필요한 하드웨어 자원은 매우 제한되어 있습니다. 메인 메모리에 대한 각 액세스는 지정된 캐시 라인에 고정되어 있습니다. 이러한 단순성과 명확성은 일련의 이점을 가지고 있습니다. 가장 큰 장점은 CPU 주파수가 200~300MHz일 때 로드 사용 지연 시간은 단 1주기만큼 빠를 수 있습니다!
일반적으로 캐시 인덱스 I는 다음과 같이 표현될 수 있습니다.
I =(Am² B)mod N
그 중 Am은 메모리 주소, B는 캐시 라인 크기, N은 총 캐시 라인 수입니다.
CPU 주파수가 증가함에 따라 Load-Use Latency도 상대적으로 줄어들고 직접 매핑의 장점은 덜 분명해지며 동시에 주 메모리 용량이 제곱 수준으로 증가하면 캐시 용량이 점점 더 작아 보입니다.
교체 전략이 없기 때문에 메인 메모리 데이터가 어느 캐시 라인에 저장될 수 있는지에 대한 선택권이 없으며, 이는 두 변수가 동일한 캐시 라인에 매핑되면 지속적으로 서로 교체된다는 의미입니다. 심각한 충돌로 인해 캐시를 자주 새로 고치면 많은 지연이 발생하며, 이 메커니즘에서는 캐시가 충분하지 않으면 프로그램의 시간 지역성이 거의 없습니다.
오늘날 직접 매핑 메커니즘은 점차 무대에서 사라지고 있습니다.
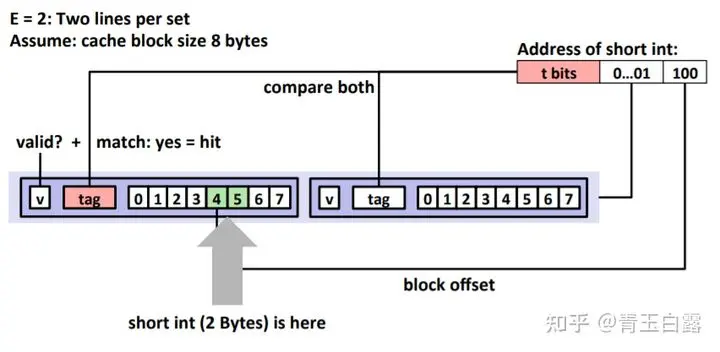
양방향 그룹 연관
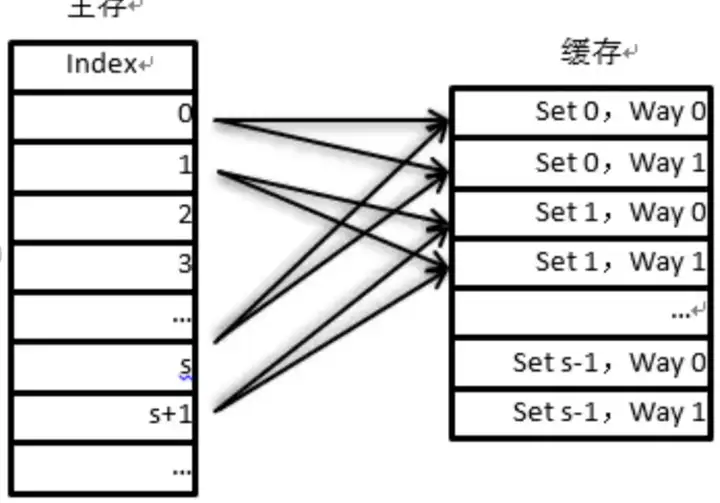
2-그룹 2-way 연관 캐시는 위 그림과 같이 s개의 그룹으로 나누어집니다. 각 그룹에는 2way라고도 하는 두 개의 캐시 라인이 있습니다. 주 메모리의 각 데이터 블록은 s 세트에만 위치할 수 있습니다. 하지만 지정된 세트의 모든 캐시 라인에 있을 수 있습니다.

양방향 세트 연관 캐시
캐시 라인과 물리적 주소 라인의 구성을 소개하기 위해 2-way 세트 연결 캐시를 예로 들어보겠습니다.
tag: 태그 비트는 way1과 way0에 대상 데이터를 저장하는 캐시 블록을 비교하는 데 사용됩니다. 그림에서 하드웨어에 구현된 두 개의 등호 비교기를 볼 수 있으며, 이는 way1과 way0의 두 태그를 비교하는 데 사용됩니다.
데이터 블록: 데이터 비트는 대상 태그의 데이터 블록(메모리와 캐시 간에 교환되는 데이터 블록)을 저장하는 데 사용됩니다.
v: 유효 비트는 캐시 블록이 유효한지 여부를 나타내는 데 사용됩니다. (복잡한 캐시 설계에는 더 많은 비트가 있을 수 있음) (예를 들어 처음에 캐시에 비어 있는 데이터 블록이 없으면 모든 v 표시는 0이 되고, 이후 데이터 블록이 로드되면 해당 블록이 유효하다는 것을 의미합니다. , 그런 다음 1로 설정합니다.)
주소는 다음 그림으로 구성됩니다. 왼쪽은 MSB이고 오른쪽은 LSB(최하위 비트)입니다.

블록 오프셋: 메모리 주소의 경우 데이터의 후속 블록 오프셋 바이트가 캐시와의 데이터 교환을 위한 블록을 형성하므로 캐시 블록의 크기를 의미합니다.
Index: 메모리 주소가 캐시 내 어느 그룹에 매핑되어야 하는지를 의미하므로 이 부분의 비트 수는 전체 캐시가 몇 개의 그룹을 보유할 수 있는지를 나타내며, 그룹 수는 각 캐시의 크기에 따라 결정됩니다. 블록의 "경로 수"(4 방향 그룹에 연결된 경로 수는 4)와 관련이 있으며 계산 방법은 다음과 같습니다.

초기 양방향 그룹 연결을 예로 들면, MemoryAddress의 집합이 2비트임을 알 수 있습니다. 그런 다음 이 메모리 주소는 집합의 2비트를 사용하여 캐시에서 해당 그룹에 해당하는지 찾을 수 있습니다. 그림에서 set의 두 자리 숫자가 10이면 세 번째 그룹 set2에 해당합니다.
사례:
4방향 연관 캐시, CPU 워드 길이는 4바이트, 메모리와 캐시는 모두 바이트 주소 지정, 캐시와 메모리 교환 단위는 블록, 각 블록 크기는 512바이트, 캐시는 1024블록을 수용할 수 있습니다. 물리적 메모리가 32비트 주소인 경우:
q1: 블록 내 오프셋 주소, 그룹 번호 및 라벨 위치를 나타내는 캐시와 메모리의 주소 형식을 그립니다.
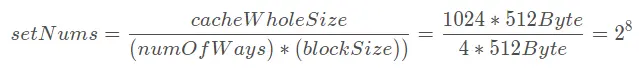
최종 결과는 다음과 같습니다.

q2: 캐시에서 메모리 주소 FAB12389(16진수)의 가능한 위치 블록 번호를 계산하십시오.
메모리 주소는 4바이트로 나뉩니다.

q1의 결과에 따르면 다음과 같이 태그, 인덱스 및 블록오프셋의 해당 값을 쉽게 얻을 수 있습니다.
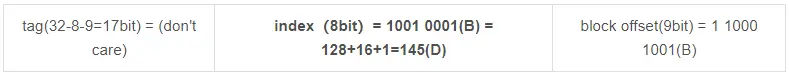
그런 다음 그룹 145에 위치합니다. 블록 번호는 왼쪽 상단에서 왼쪽에서 오른쪽으로, 위에서 아래로 증가하므로 그룹 145에 위치한 블록의 블록 번호가 답입니다: 145*4 + (0 ,1,2,3) = 580,581,582,583 블록

양방향 집합 연관 캐시 구성
이미지 출처: https://www.sciencedirect.com/topic s/computer-science/set - associative-cache
AMD Athlon의 L1 캐시는 이 양방향 집합 연관 매핑 방법을 사용합니다.
N방향 그룹 연관
2방향 집합 연관에 비해 더 일반적인 방법은 n방향 집합 연관입니다. 즉, 캐시는 s개의 그룹으로 나누어지고, 각 그룹은 n개의 캐시 라인으로 구성됩니다.
일반적으로 캐시 인덱스 I는 다음과 같이 표현될 수 있습니다.
그 중 Am은 메모리 주소, B는 캐시 라인 크기, N은 각 그룹의 웨이(ways) 수, S는 그룹 수를 나타낸다.
8방향 집합 연관은 각 그룹에 8개의 행이 있음을 의미합니다.
완전히 연결됨
완전 연관성은 집합 연관성의 극단적인 형태로, 이 매핑 관계는 메인 메모리의 데이터 블록이 모든 캐시 라인에 나타날 수 있음을 의미합니다. 이 대체 알고리즘은 가장 큰 유연성을 가지며 이는 또한 가장 낮은 실패율을 가질 수 있음을 의미합니다. 동시에, 사용할 인덱스가 없기 때문에 캐시 적중 시 전체 캐시 범위 내에서 검색이 필요한지 여부를 확인하므로 검색 회로에 많은 지연이 발생합니다. 따라서 이 연결 방법은 캐시가 매우 작은 경우에만 가능합니다.
요약
메인 메모리와 캐시를 연관시키는 방법의 선택은 여러 요소 간의 절충의 결과입니다. 예를 들어, 특정 대체 전략을 통해 주 메모리 데이터 블록에 해당하는 10개의 캐시 라인이 있을 때 프로세서는 이 10개의 위치를 검색하여 그중 하나가 적중하는지 확인하는 방법을 찾아야 합니다. 검색이 많을수록 전력 소비가 커지고 칩 면적이 커지고 시간이 길어진다는 의미이며, 다른 관점에서 보면 해당 항목이 많을수록 누락률이 낮아져 느린 메인 메모리에서 데이터를 검색하는 데 걸리는 시간이 줄어듭니다.
연구에 따르면 N의 방법 수를 두 배로 늘리면 캐시 영역을 두 배로 늘리는 것과 거의 동일한 양만큼 캐시 적중률을 향상시킬 수 있습니다. 그러나 경로 수가 4개를 초과하는 경우에는 적중률의 향상이 그리 뚜렷하지 않습니다. 다른 연구(참조 2, 3)에서는 단일 단계 캐시에 관한 한 8-way 집합 연관 방법이 실패율 측면에서 완전 연관 방법과 동일한 효과를 갖는 것으로 나타났습니다. 많은 CPU는 단지 실패율을 줄이기 위해서가 아니라 16방향 또는 32방향 그룹 연관 방법을 사용합니다.
N방향 세트 연관 캐시 구조
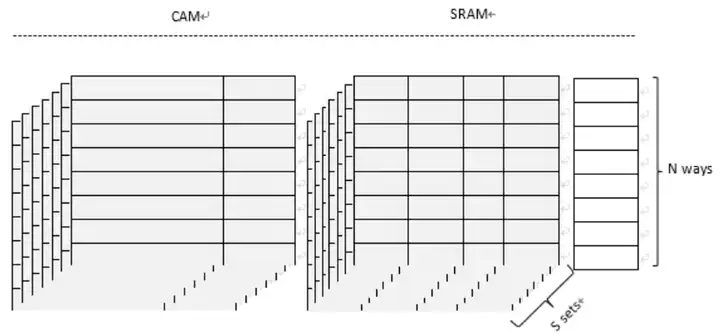
N방향 그룹 연결
위 그림과 같이 캐시 라인을 두 부분으로 나누어 저장하며, 병렬 검색(Parallel Search)이 용이하도록 RAT와 Status 비트를 CAM(Content Addressable Memory)에 저장하는데, 직렬 검색(Sequential Search)과 비교하면, 병렬 검색은 더 빠른 속도를 얻을 수 있지만 Way의 수가 많을수록 상당한 양의 물리적 자원이 필요합니다. 대부분의 최신 아키텍처에서 데이터 필드는 일반적으로 다중 포트, 다중 뱅크 SRAM 어레이를 사용합니다.
CAM에는 NAND와 NOR의 두 가지 유형이 있으며 NOR CAM은 병렬 검색을 사용하고 NAND CAM은 계단식 검색을 사용합니다. 각 캐시 라인에 더 많은 정보가 포함되므로 NOR CAM을 사용할 때 더 많은 전력이 필요하며 구현상의 이유로 경로가 많을수록 대기 시간이 길어집니다(참고 4). NAND CAM은 원 푸시 방식을 채택하여 더 낮은 전력 소비 요구 사항.
CAM은 특정 장치가 히트하는지 여부를 판단하는 것 외에도 회로의 구동 문제도 찾아야 합니다. 게이트 회로의 구동 성능은 전류, 주파수, 매체 등과 같은 여러 요소와 관련됩니다. 드라이브 성능을 향상시키는 방법에는 금속 미디어 사용, 멀티 레벨 드라이브 적용, 배선 거리 단축 등 여러 가지가 있습니다. 그러나 이러한 방법은 전력 소비를 늘리거나 대기 시간을 연장시킵니다. 물론 일부 사람들은 검색을 완료하기 위해 파이프라인 방법과 더 많은 비트를 사용하는 것을 제안했지만 이는 가능한 한 적은 비트로 캐시 읽기 및 쓰기 작업을 완료하려는 주요 제조업체의 목표와 분명히 반대됩니다. 여러 가지 이유로 최신 프로세서에서 L1 캐시와 관련된 방식의 수는 그리 많지 않습니다.
현재 대부분의 CPU는 2-Ways, 4-Ways, 8-Ways 또는 16-Ways 그룹 결합을 사용하며 하드웨어 구현을 용이하게 하기 위해 경로 수는 대부분 2의 거듭제곱입니다. 물론 예외는 없습니다. 일부 CPU에는 시스템에 채널이 10개 또는 12개 있는데, 이러한 현상이 나타나는 이유는 채널 수가 정확하지 않기 때문입니다. 주변 장치에서는 CPU와 주변 장치 모두 그래픽 카드나 다양한 PCIe 장치와 같은 주 메모리에 액세스할 수 있습니다. 대부분의 경우 CPU는 LSQ, FLC, MLC를 거쳐 최종적으로 LLC를 통해 주 메모리와 데이터를 교환하며, 주변 장치가 DMA 액세스를 수행할 때 LLC와 주 메모리를 직접 마주하게 됩니다. , L1 캐시에 손상을 초래하며 간접적인 영향을 미칩니다. 이러한 차이로 인해 프로세서의 LLC 경로 수가 2의 여러 거듭제곱의 합이 됩니다.
액세스 경로의 불일치 외에도 비피어 경로를 만드는 또 다른 이유는 실패율을 줄이기 위한 것입니다. 예를 들어 Skewed-Associative 캐시(참조 5)는 두 개의 해시 알고리즘을 사용하여 그룹 내 두 개의 서로 다른 경로를 매핑하므로 그룹 및 경로 수를 늘리지 않고도 누락률을 효과적으로 줄일 수 있습니다.
어떤 경우에는 TLB 미스처럼 캐시 미스로 인한 비용이 감당할 수 없을 정도로 크며, 스토리지 소프트웨어든 하드웨어 지원이든 관계없이 미스로 인한 비용은 너무 비쌉니다. 완전 연관 구현을 선택했습니다. TLB의 설계도 Hit time과 Hit rate 사이에서 절충을 해야 하므로 TLB는 두 가지 레벨로 나누어진다. 적중률에 대한 추가 고려가 필요하며 일반적으로 문제의 크기가 비교적 크며 N-way 그룹 연관 방법을 채택합니다.